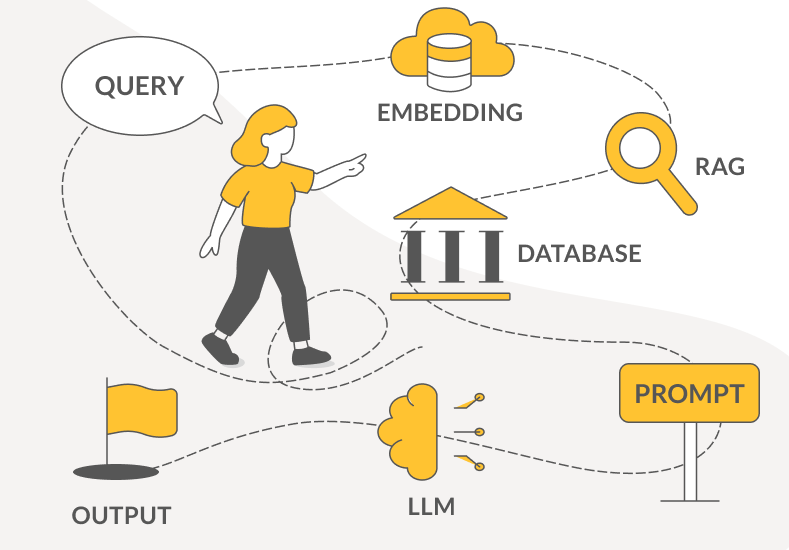
Retrieval Augmented Generation (RAG) is a method for directly connecting a large language model (LLM) with external data. This helps reduce the much-dreaded hallucinations, and ensures the LLM’s answers remain up to date by drawing on current information. In principle, the system is quite straightforward, although in practice it requires careful structural planning, explain EuroCC Austria experts Martin Pfister, Thomas Haschka and Simeon Harrison in an interview with Bettina Benesch.
Before we dive into the interview, here’s a brief introduction to the world of RAG: What exactly is RAG? The abbreviation stands for Retrieval Augmented Generation and refers to a method for linking a large language model (LLM) such as ChatGPT or Mistral with external data, thereby extending its capabilities.
To understand RAG more clearly, it’s important to know how an LLM is trained: it is fed billions of data points and trained to answer a wide variety of questions based on that data. For example, it might learn how to write Python code. If a user then asks the model, “Write me a script that retrieves and stores weather data from a website,” the LLM – ideally – produces a correct script. That’s how a classic LLM functions: it learns from the data it has been trained on. This means it runs into limitations with topics it hasn’t previously encountered. It simply doesn’t have the answer.
Time is also a limiting factor: the training data is drawn from a specific cut-off date. The model itself has no built-in way of accessing current information.
This may not matter in our Python example, but if someone wants to know who was appointed Austria’s Minister for the Environment in 2025, the training data from 2024 won’t be of much help. This is where hallucinations occur – the LLM makes up answers when it lacks access to suitable data. While this happens less frequently today than a few years ago, it remains a source of frustration.
To address this, the RAG approach was introduced in 2020, enabling the model to access external, up-to-date data. Imagine a school pupil in 1990 who needs to prepare a presentation on nuclear power (1990: no internet, certainly no ChatGPT). He might know what a reactor looks like from films and have a vague idea that it produces electricity, but not which components are involved or how the risks and benefits compare. So he heads to the library, finds a relevant book, and learns what he needs to know. RAG works in much the same way: it acts as a bridge between the LLM and external data sources.
RAG brings out the best in LLMs. It specifically enriches prompts by tailoring them to draw on external information. A typical prompt like “How does VAT work in Austria?” becomes under RAG something like, “Based on the following documents: [Doc 1: VAT Act 1994, Doc 2: XY.pdf], how does VAT work in Austria?”
If you ask ChatGPT today, for instance, “What railway discount cards are currently available in Austria?”, you’ll receive an accurate list of available offers, often with a source link. This is because OpenAI, which operates ChatGPT, employs the RAG approach. A few years ago, the LLM might have made something up or responded, “Sorry, I don’t know.”
This method is brilliant for enterprise chatbots: if a customer asks about a particular product, the LLM can consult internal documents and return relevant results. It also works for internal use: if an employee wants to know how many days of annual leave they have remaining, the LLM can virtually consult HR documents and provide the correct answer. RAG can also be used to pull in current data from social media, news sites, or public databases – with source references, if required. Another plus: it’s cost-effective.
However, there are a few important considerations when implementing RAG. And that’s what this conversation is about:
Thomas Haschka: Of course. Let’s say someone asks, “Who became President of the United States in 2025?” That question wouldn’t be answered directly by the LLM, but rather via a search engine query. With RAG, the question passed to the LLM becomes: “Based on the following information: [results from the search engine], who became President of the United States in 2025?” Since the answer is already known, the LLM can respond correctly. The real skill in RAG lies in how the third-party information is gathered, injected into the prompt, and structured – and this is the subject of ongoing research.
“
The real skill in RAG lies in how the third-party information is gathered, injected into the prompt, and structured – and this is the subject of ongoing research.
„
RAG builds on prompt engineering – incorporating external data into prompts. While RAG is fairly straightforward in principle, evaluating it and developing it into a real product can be complex. There are many ways to go about it. A common approach is to use a vector database such as ChromaDB in combination with LangChain – essentially a toolkit for integrating external data into prompts.
Simeon Harrison: In this case, the LLM is mainly responsible for providing natural-sounding language.
“
RAG expands the prompt dynamically, depending on the nature of the question, with information likely to be helpful in producing an answer. Rather than working from a fixed list of ten well-crafted prompts, the prompt is adapted specifically for each query.
„
Thomas Haschka: Absolutely. The example I just gave is one of many possible applications. It’s currently very popular to extract information from PDFs. If a user is looking for something specific in a hundred-page dissertation, the LLM can find it in the provided PDF and ideally give a response based on that data.
This makes it possible to eliminate hallucinations and limit responses to a company’s own data. A chatbot on a business website, for example, will only provide information about the company – and nothing else.
Martin Pfister: The step from prompt engineering to RAG is a natural progression. You might say RAG is prompt engineering on steroids. Instead of simply appending a single query to the prompt, RAG expands it dynamically, depending on the nature of the question, with information likely to be helpful in producing an answer. Rather than working from a fixed list of ten well-crafted prompts, the prompt is adapted specifically for each query.
Thomas Haschka: When LLMs first came onto the scene around 2018, I don’t think people really realised what they were capable of. Then, in 2020, someone simply decided to try feeding external content into a prompt.
Simeon Harrison: Although RAG only became truly viable once models could handle longer input sequences. That was a limitation before 2020. Even so, LLMs were already hugely useful for things like analysing customer reviews – to find out what people thought about a product or brand. Their chat and content-generation capabilities came later.
Thomas Haschka: The tools are evolving all the time – it’s a fast-moving field. In general, you need a trained LLM, an embedding model, and a vector database that can quickly deliver relevant information in response to a query.
Thomas Haschka: RAG can process internal documents that the LLM wasn’t originally trained on. You get accurate answers by instructing the LLM to respond only when the relevant data is present in the provided documents. It can also reflect on its own output using chain-of-thought techniques – feeding its own answer back into the prompt and asking it to evaluate it before finalising the response.
“
The tools are evolving all the time – it’s a fast-moving field. In general, you need a trained LLM, an embedding model, and a vector database that can quickly deliver relevant information in response to a query.
„
Simeon Harrison: If you want your model to use highly specialised language – medical or legal, for example – RAG alone won’t be enough. You’ll likely need a fine-tuned model, although you can still use it alongside RAG.
Thomas Haschka: Data retrieval can be difficult, and as mentioned, RAG can’t always replace fine-tuning or dedicated model training. You also need to be very deliberate about what information you feed into the prompt, and how you obtain that information. The system needs to be tested thoroughly to ensure it delivers the correct answers, and that the right data is being injected into the prompt.
Semantics are a major challenge. RAG systems search for similar text passages in response to a query – essentially, they look for similar words. So the system has to find the right context for each query, which can be tricky. Take the earlier example: a 100-page PDF – a dissertation – and you want to know what’s in Chapter Five. The issue is how to resolve that semantically. “Chapter One”, “Chapter Two”, and “Chapter Three” sound similar to “Chapter Five”. So you might get back the first ten lines of all ten chapters. How do you know which one is the right answer? These are the kinds of challenges that RAG researchers are grappling with.
“
Humans understand the difference between "I’m not going to the cinema today" and "I’m staying home today". However, the LLM sees both as similar, which is clearly incorrect. These are the challenges of working with RAG. It’s a rapidly evolving field.
„
Thomas Haschka: Using embedding models. But they’re not perfect.
Thomas Haschka: An embedding model is like a translator – but instead of converting words into another language, it converts them into numbers. You end up with a string of numbers the computer can understand and compare. An embedding model might take the sentence “The dog runs in the garden” and turn it into a vector – a list of, say, 300 numbers. These numbers encode the meaning of the sentence. Similar sentences get similar vectors – like “A dog is running outside.” RAG uses these embeddings to find texts that match a query. For example, you might ask, “How does an electric motor work?” The system turns the question into a vector, searches a database for documents with similar vectors, and retrieves relevant content. The LLM then uses that content to answer the question.
Here lies the major problem I mentioned earlier: humans understand the difference between “I’m not going to the cinema today”, “I’m going to the cinema today”, and “I’m staying home today”. But the LLM sees “I’m not going” and “I’m going” as more similar than “I’m not going” and “I’m staying home”. So almost every embedding model would get this wrong – it would group “I’m not going” and “I’m going” together, which clearly isn’t correct. These are the challenges of working with RAG. It’s a rapidly evolving field.
Thomas Haschka: Definitely. Embedding is widely used in practice and works well enough to build functional products. It’s not perfect – but it works.
Simeon Harrison: RAG is probably the most practical method for businesses to benefit from LLMs. It allows them to build effective website chatbots and other tools, and it’s an affordable solution.
Keen to learn more about RAG? EuroCC Austria regularly offers training sessions on this and other topics. Click here for upcoming courses from EuroCC Austria/VSC.
Thomas Haschka
Thomas made his way from simulation and biophysics to data science and ultimately to artificial intelligence. He earned his PhD in France and conducted research at the Muséum National d'Histoire Naturelle, Institut Pasteur, and the Paris Brain Institute. Before returning to TU Wien, he spent over a year teaching artificial intelligence at the American University of Beirut.
Martin Pfister
Martin studied physics at TU Wien and is currently pursuing a doctorate in medical physics at MedUni Wien. At EuroCC Austria, he helps clients run projects on the Austrian VSC Supercomputer and teaches Deep Learning and Machine Learning.
Simeon Harrison
Simeon is a trainer at EuroCC Austria, specialising in Deep Learning and Machine Learning. A former mathematics teacher, he receives feedback from course participants such as: "Simeon Harrison is an excellent teacher. His teaching style is clear, engaging, and well-structured, making the topics more enjoyable to learn.”


