HAKOM
Zeitreihen im Energiesektor: erfolgreiches Big Data Projekt von HAKOM
HAKOM, der Technologieführer für Zeitreihenmanagement in der Energiewirtschaft, reagiert auf die Nachfrage des Marktes nach schnellerer Verarbeitung von immer größeren Datenmengen. Um das bereits beeindruckende Repertoire an Lösungen noch um fortschrittlichere Big-Data-Analysefunktionen zu erweitern, testete das Unternehmen seine Technologie auf einem Supercomputer. Kleiner Cluster, große Daten, hohe Leistung – der Use Case von HAKOM zeigt, wie High-Performance Computing die Datenanalyse optimiert.
Wie praktisch jede andere Branche durchlebt auch der Energiesektor eine digitale Transformation. Die um sich greifenden Technologien des Internets der Dinge und Industrie 4.0 treiben diesen Prozess voran und erzeugen mehr Daten als je zuvor. Bei den meisten davon handelt es sich um Zeitreihendaten, oder einfach gesagt um Daten, die mit einem Zeitstempel versehen sind.
Zeitreihen
In der Energiewirtschaft werden Zeitreihendaten durch messtechnische Größen der Anlagen wie Netzfrequenz und Spannungsschwankungen, sowie durch die Aufzeichnung von Wetter und meteorologischen Bedingungen erzeugt, z.B. Temperatur, Windstärke, Globalstrahlung und Luftfeuchtigkeit.
In den letzten drei Jahren sind die Datenmengen, die Energieversorger generieren und von den NutzerInnen erhalten, drastisch gestiegen. Die zunehmende Menge an hochfrequenten Daten stellt eine Herausforderung dar – sie alle müssen gespeichert, harmonisiert, aggregiert und analysiert werden. Darüber hinaus steigen die Anforderungen an eine effiziente Verarbeitung der Daten, die nahezu in Echtzeit erfolgen muss. Eine zeitnahe Analyse ist unerlässlich für Prognosen, Kapazitätsplanung, Verbesserung der Energieeffizienz, Erschließung neuer Einnahmequellen sowie für die Vermeidung von Stromausfällen.
Aufbruch in ein neues Datenmanagement
"Energieversorger sind mit den ständig wachsenden Datenmengen extrem gefordert, und der Löwenanteil dieser Daten sind Zeitreihen", bestätigt Stefan Komornyik, Managing Partner bei HAKOM. Seit dreißig Jahren bietet das Wiener Unternehmen Lösungen für die Verwaltung, Speicherung und Verarbeitung von Zeitreihendaten und hat dabei alle Herausforderungen der Branche über die Jahre hinweg gemeistert. Heute ist klar, dass ein Paradigmenwechsel im Datenmanagement notwendig ist, um die Datenflut zu beherrschen und aus Zeitreihendaten wichtige Einblicke zu gewinnen.
"Standardisierung muss in allen Bereichen des Datenmanagements das Ziel sein, um innovative Lösungen anbieten zu können", so Komornyik. "Auf Basis voll skalierbarer Basistechnologien können hochskalierbare Applikationen für Daten unterschiedlicher Quellen und Formate in kurzer Zeit entwickelt werden. Einer ganz speziellen Eigenschaft der HAKOM Zeitreihentechnologie kommt hier eine besondere Bedeutung zu – der Polyglot Persistence. Dies ist die Möglichkeit Daten, die in unterschiedlichen Technologien verspeichert werden, konsistent und performant zusammenzuführen. So wird es möglich, den Wert der Daten, die an unterschiedlichen Quellen entstehen, zu maximieren, und für jeden Use Case die passende Datenbanktechnologie einsetzen zu können, ohne jedes Mal große Teile der Applikation neu entwickeln zu müssen."
Little Big Data Cluster
Für Unternehmen, die sich mit neuen Basistechnologien auseinandersetzen und rechenintensive Aufgaben wie Big Data Analytics bewältigen wollen, gibt es die Möglichkeit, technische Unterstützung aus dem Netzwerk von EuroCC Austria zu erhalten. Auf diesem Wege wurde HAKOM an die ExpertInnen des
Little Big Data Clusters vermittelt, einem High-Performance Computing (HPC) System an der TU Wien. Auf dem LBD-Cluster können NutzerInnen ihre eigene Umgebung erstellen und verschiedene Softwareversionen testen. Da das System vor allem für Angehörige der TU Wien zur Verfügung steht, bietet EuroCC Austria für Unternehmen, die im Rahmen eines „Proof of Concept“ (PoC) die Möglichkeiten von HPC ausloten möchten, Zugang zu dem für sie am besten geeigneten Cluster an.
Proof of Concept: High-Performance Data Analytics
Bei dem PoC arbeitete HAKOM mit einem Datensatz, der deutlich größer ist als die von HAKOM-Kunden typischerweise verwendeten Mengen: 5.300.000 Beobachtungen verschiedener Zeitreihen in Messintervallen von jeweils 2 Sekunden.
Basierend auf bestehender Zeitreihentechnologie erstellte HAKOM einen Prototyp, der Transaktionsdaten aus einem verteilten Dateisystem nutzen kann, um die Zeitreihendaten zu speichern und einfache, aber sehr rechenintensive Statistiken zu berechnen.
Bei Verwendung der PostgreSQL-Datenbank für die Bewegungsdaten mit sequenzieller Speicherung waren diese Statistiken praktisch unmöglich innerhalb eines akzeptablen Zeithorizonts zu berechnen – die Berechnungszeit lag im Bereich von vielen Stunden. Der Durchbruch gelang mit einem verteilten, skalierbaren Dateisystem und einer parallelisierten Speicherung auf mehreren Knotenpunkten. Dadurch konnte HAKOM die Verarbeitung von hochfrequenten Zeitreihendaten um den Faktor 400 beschleunigen und auf etwa sechs Minuten reduzieren.
Dies zeigt neuerlich eindrucksvoll einen der Hauptvorteile von Supercomputing: Die Möglichkeit, Probleme zu parallelisieren, d. h. ein großes Problem effizient in mehrere kleinere Probleme aufzuteilen und jedes von ihnen separat, dafür zeitgleich zu lösen. Dadurch wird der Code beschleunigt und die Berechnungszeiten entsprechend verkürzt. So profitieren Unternehmen durch den Einsatz von HPC in vielen Hinsichten und können komplexe rechenintensive Probleme bearbeiten und lösen, Software optimieren, die Produktentwicklung beschleunigen und time-to-market verkürzen.
Wie geht es weiter?
Die erfolgreiche Integration der Zeitreihenmanagement-Plattform in den LBD-Cluster wird es HAKOM künftig ermöglichen, die Analyse sehr großer Datenmengen direkt über sein System weiterzuentwickeln. Dazu werden verschiedene Modalitäten untersucht, um verteilte Analysen sowohl auf der HAKOM-eigenen Infrastruktur als auch innerhalb der Cloud anzubieten. Werkzeuge zur Analyse und Verarbeitung von Zeitreihen sind bereits in der Cloud als HAKOM TSM Hosted Lab zu Testzwecken verfügbar. Mitte des Jahres wird das Unternehmen ein cloudbasiertes Zeitreihenservice für den Energiemarkt auf den Markt bringen, das sowohl für einfache Use Cases auf Basis einiger weniger Zeitreihen im 15 Minuten Raster bis zu Anwendungsfällen auf Basis von einigen hunderttausend Zeitreihen aus Sensordaten im Sekundenraster sowohl die Verarbeitung als auch das Verspeichern der Daten in der Cloud umfasst.
EuroCC Austria – Anlaufstelle für HPC
Das Experiment von HAKOM mit High-Performance Big Data Analytics ist ein weiteres erfolgreiches Outreach-Projekt von EuroCC Austria, dessen Mission es ist, einem breiten NutzerInnenkreis Zugang zur HPC-Infrastruktur und Know-how zu verschaffen. Durch die Zusammenarbeit mit EuroCC Austria können Unternehmen HPC, Big Data Analytics oder künstliche Intelligenz erproben, übernehmen und in ihre Geschäftsmodelle einbinden – zur Produktoptimierung und Weiterentwicklung fortschrittlicher Produkte und Technologien.
Die Serviceleistungen von EuroCC Austria stehen Unternehmen, Forschenden und öffentlichen Einrichtungen kostenlos zur Verfügung. Kontakt für Anfragen: info@eurocc-austria.at.
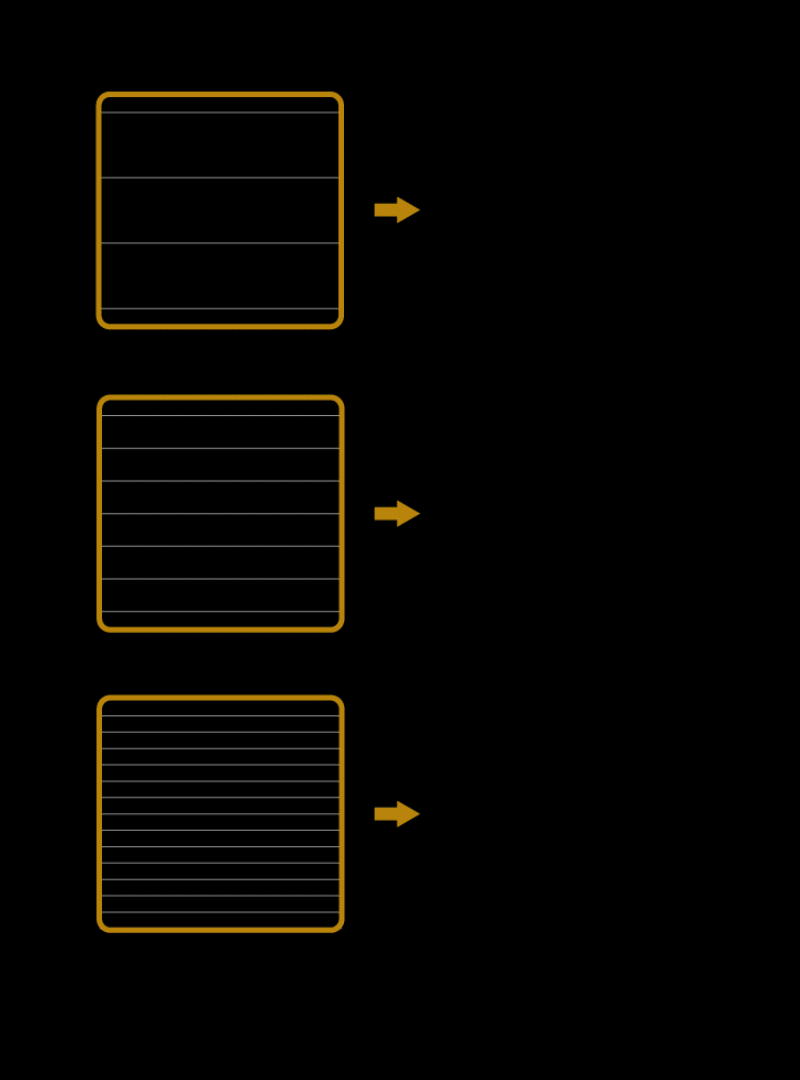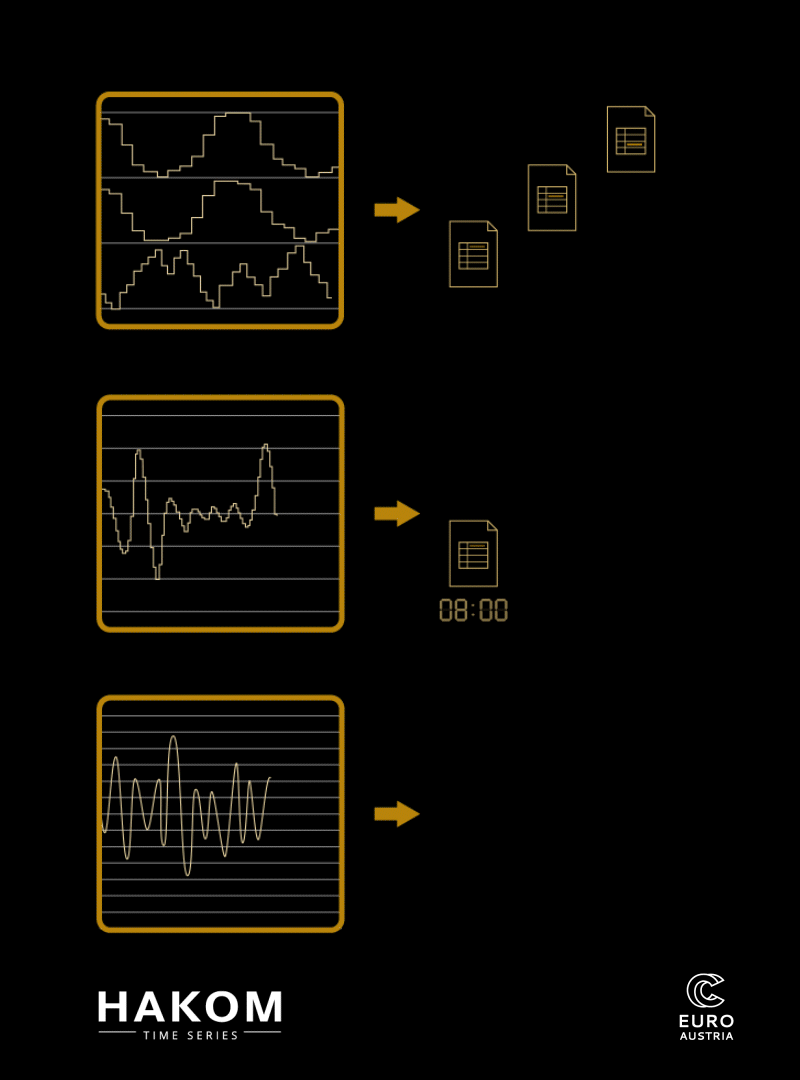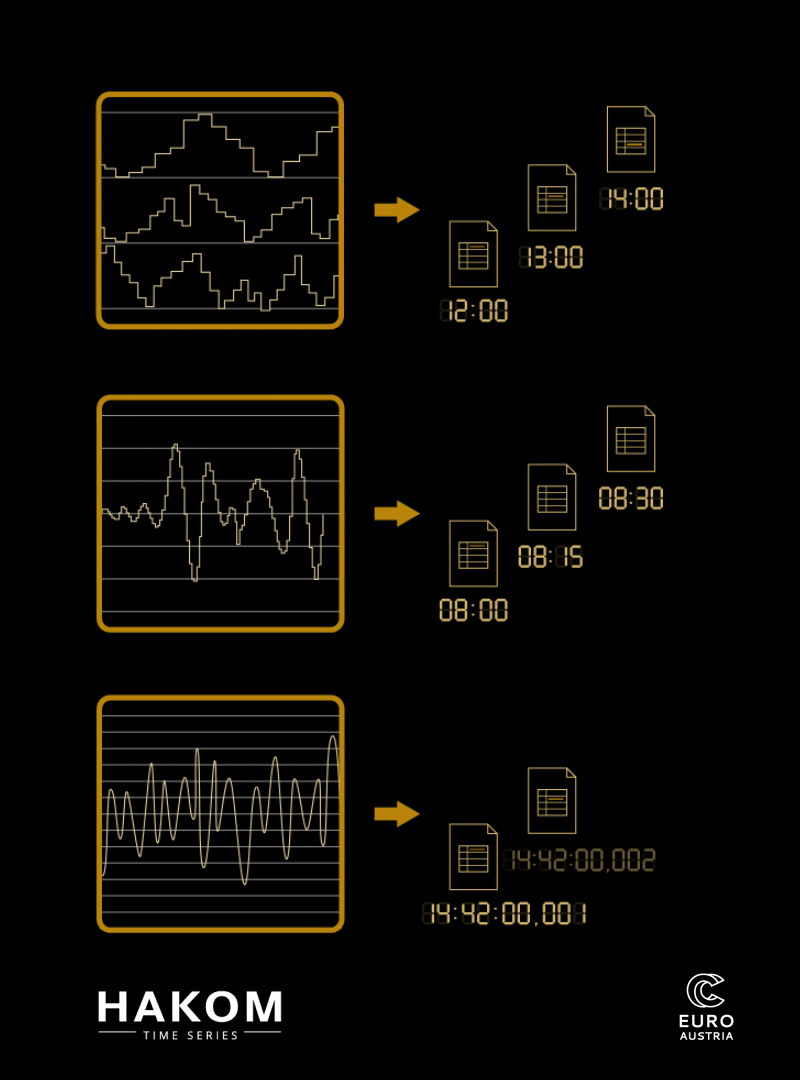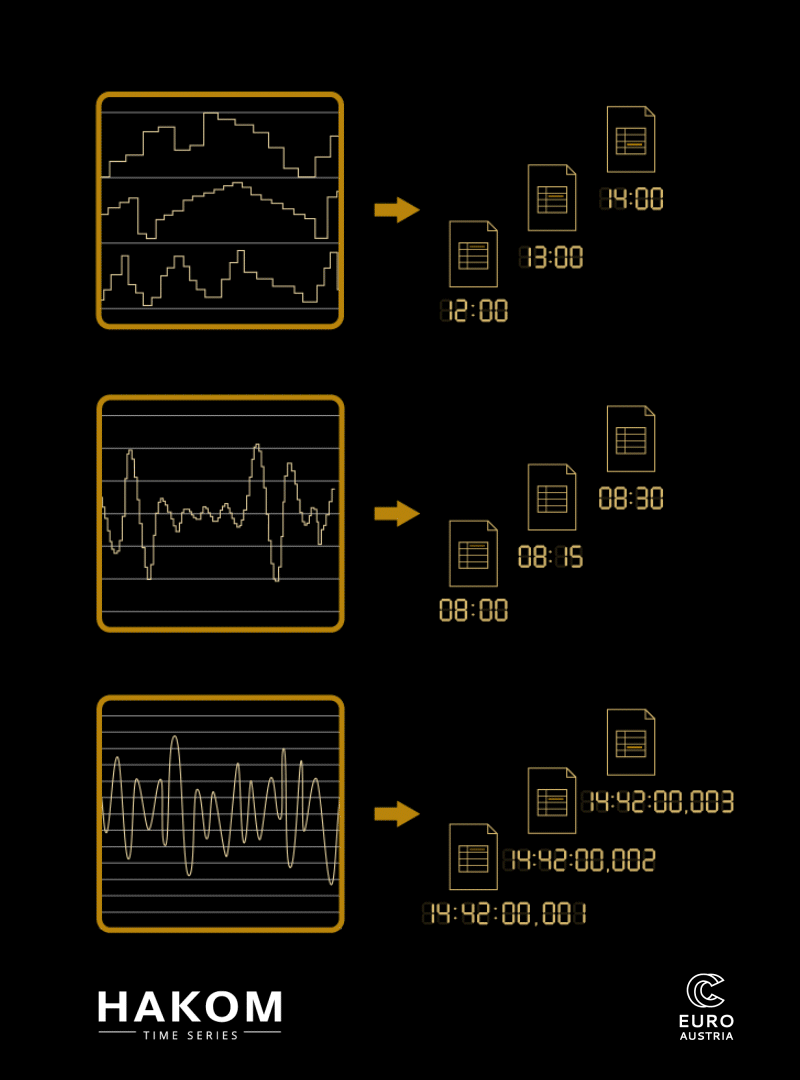
Zeitreihen mit variablen Zeitrastern und Qualitäten © EuroCC Austria
Little Big Data Cluster
LBD is ein Hadoop Cluster mit 20 Knoten und Anwendungen wie Apache Spark, Hive, Cassandra, MongoDB und Kafka. Das Team des dataLABs passt das Angebot flexibel an die Anforderungen der NutzerInnen an, um sie bei den Projekten bestmöglich zu unterstützen. Weitere Infos zur Servicestelle "Information Technology Solutions" (TU.it) an der TU Wien
hier
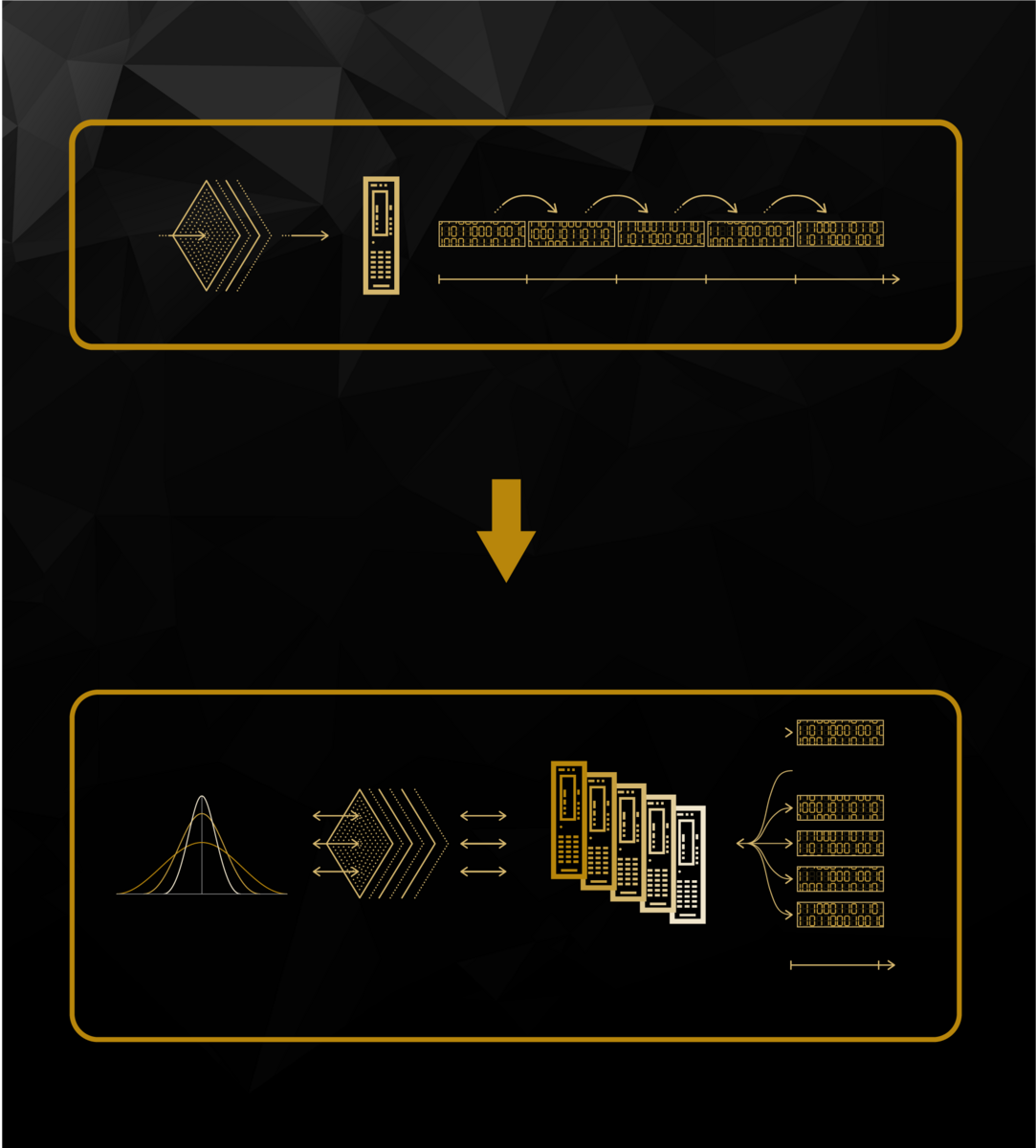
Sequentielle vs. parallele Datenspeicherung
© EuroCC Austria