Retrieval Augmented Generation (RAG) ist ein Weg, um ein Large Language Model direkt mit externen Daten zu verbinden. So lassen sich zum Beispiel die gefürchteten Halluzinationen reduzieren und die Antworten des LLMs sind aktuell, da es auch auf aktuelle Daten zugreift. Vom Prinzip her ist das System sehr simpel, im individuellen Fall muss man jedoch den einen oder anderen Gedanken an eine solide Struktur verwenden, erklären die EuroCC-Austria-Experten Martin Pfister, Thomas Haschka und Simeon Harrison im Interview mit Bettina Benesch.
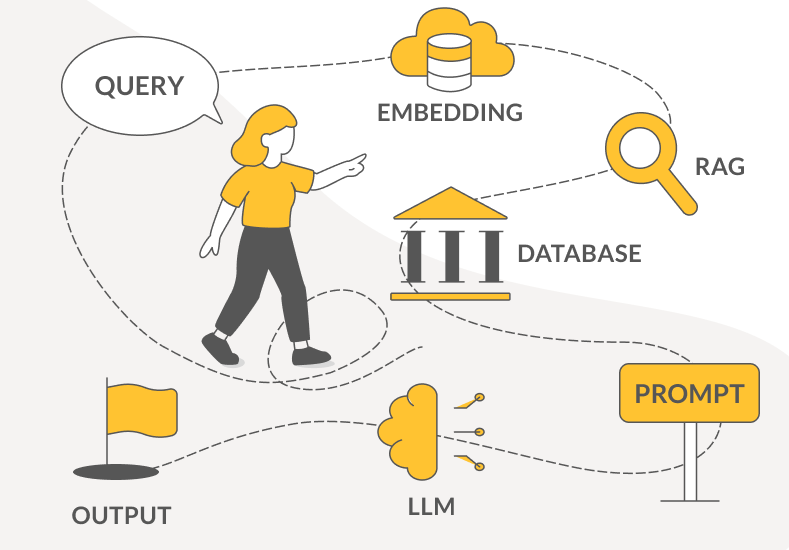
Bevor es hier gleich zum Interview geht, ein kleiner Exkurs in die Welt von RAG: Was ist RAG überhaupt? Die Abkürzung steht für Retrieval Augmented Generation und bezeichnet eine Methode, um ein Large Language Model (LLM) wie ChatGPT oder Mistral mit externen Daten zu verbinden. So wird das LLM erweitert.
Um den Sinn hinter RAG genauer zu verstehen, muss man wissen, wie ein LLM entsteht: Es erhält Milliarden von Daten und wird damit trainiert, um am Ende anhand dieser Daten alle möglichen Fragen zu beantworten. Das Modell lernt zum Beispiel, wie man Python-Code programmiert. Fordert ein User das trainierte Modell auf: „Code mir ein Skript, das Wetterdaten von einer Webseite abruft und speichert“, liefert das LLM – im besten Fall – ein korrektes Skript. So funktioniert also ein klassisches LLM: Es lernt aus Daten, mit denen es gefüttert wurde. Daher stößt es auf Grenzen bei all jenen Themen, die es zuvor nicht erfahren und gelernt hat. Es hat die Antworten nicht parat.
Auch die Zeit spielt hier begrenzend mit: Die Trainingsdaten wurden zu einem bestimmten Datum erstellt und dem LLM zur Verfügung gestellt. Das Model hat also von sich aus keine Möglichkeit, an aktuelle Daten zu kommen.
Im Fall unseres Python-Beispiels ist das zwar einerlei, aber wer wissen möchte, wie der österreichische Umweltminister heißt, der 2025 angelobt wurde, kommt mit den Trainingsdaten aus 2024 nicht weit. So passiert es immer wieder, dass ein LLM sich Antworten ausdenkt, wenn es nicht mit den passenden Daten trainiert wurde. Das wird als Halluzinieren bezeichnet; ein bekanntes Problem, das zwar nicht mehr so häufig vorkommt wie noch vor einigen Jahren – aber doch immer noch oft genug, um für Unmut zu sorgen.
Vielleicht um die Menschen wieder mit LLMs zu versöhnen, entstand 2020 der RAG-Ansatz, der dem Modell den Zugang zu externen, aktuellen Daten ermöglicht. Man kann sich das vorstellen wie bei einem Schüler aus dem Jahr 1990, der ein Referat über Atomkraftwerke halten soll (1990: kein Internet, noch lange kein ChatGPT). Er weiß zwar aus Filmen, wie das Gebäude aussieht, und vielleicht hat er eine Ahnung davon, dass es irgendwie Strom produziert – aber welche Teile verbaut sind und welcher Nutzen welchem Risiko gegenübersteht, davon hat er keinen Schimmer. Also macht er sich auf den Weg von der Schule in die Bibliothek, schnappt sich ein Buch zum Thema und findet darin alles über Atomkraftwerke, was er sucht. RAG ist so etwas wie der Weg zur Bibliothek: Eine Verbindung zwischen LLM und externen Daten.
RAG holt das beste aus LLMs heraus. Ganz konkret modifiziert es die Prompts, indem es diese so verändert, dass das LLM auf spezifische externe Informationen zugreift. Ein normaler Prompt wie „Wie funktioniert die Umsatzsteuer in Österreich?“ wird durch RAG zu etwas wie „Basierend auf den folgenden Dokumenten: [Doc 1: UStG 1994, Doc 2: XY.pdf] Wie funktioniert die Umsatzsteuer in Österreich?“
Fragt man ChatGPT zum Beispiel heute: „Welche Vorteilskarten für die Bahn gibt es derzeit in Österreich?“, erhält man eine Auflistung aller aktuellen Ermäßigungskarten, und dazu den Link zur Quelle. Weil der ChatGPT-Betreiber OpenAI den RAG-Ansatz nutzt. Vor ein paar Jahren hätte das LLM irgendetwas erfunden oder gesagt, „Sorry, ich weiß es nicht“.
Die Methode ist genial für Chatbots in Unternehmen: Fragt ein Kunde zum Beispiel nach einem bestimmten Produkt, kann das LLM auf interne Dokumente zugreifen und die gewünschten Produkte anzeigen. Das funktioniert auch intern: Möchte eine Mitarbeiterin wissen, wie viel Urlaubstage ihr noch zur Verfügung stehen, schlendert das LLM virtuell kurz in die Personalabteilung, nimmt dort Einsicht in das entsprechende Dokument und kommt mit der richtigen Antwort retour. RAG lässt sich auch nutzen, um andere aktuelle Quellen anzuzapfen, wie soziale Medien, Nachrichtenseiten oder öffentliche Datenbanken. All das auf Wunsch mit Quellenangabe. Ein weiterer Vorteil von RAG: Das Ganze ist kostengünstig.
Es gibt allerdings ein paar Dinge, die man beachten sollte, wenn man RAG implementiert. Und darum geht es in unserem Gespräch:
Thomas Haschka: Klar. Nehmen wir die Frage „Wer wurde 2025 Präsident der Vereinigten Staaten?“. Die Antwort wird nicht direkt über das LLM beantwortet, sondern über eine Suchmaschinensuche. Mit RAG wird die Frage an das LLM weitergegeben: „Unter den vorliegenden Informationen: [Resultate der Suchmaschinenanfrage] gib Auskunft zur Frage: Wer wurde 2025 der Präsident der Vereinigten Staaten?“ Da das Resultat bereits bekannt ist, kann das LLM richtig antworten.
Die Art der Ermittlung der dritten Informationen, des Einschleusens dieser Information beziehungsweise der Aufbau der resultierenden Prompts: Das zusammengefasst ist die Kunst des RAG und ein aktives Forschungsfeld.
“
Die Art der Ermittlung der dritten Informationen, des Einschleusens dieser Information beziehungsweise der Aufbau der resultierenden Prompts: Das zusammengefasst ist die Kunst des RAG und ein aktives Forschungsfeld.
„
Die Idee von RAG geht auf das Prompt Engineering zurück; dass man externe Daten in den Prompt einfließen lässt. In der Praxis ist RAG eine recht simple Sache, aber es ist sehr kompliziert, es zu evaluieren und dann auch wirklich ein Produkt daraus zu bauen. Wie man das macht, da gibt es alle möglichen Varianten. Die Standardvariante ist, eine Vektordatenbank wie ChromaDB in Verbindung mit LangChain zu verwenden, also im Grunde nichts anderes als eine Bibliothek, um die externen Daten in den Prompt einfließen zu lassen.
Simeon Harrison: Das Large-Language-Modell wird in diesem Fall nur verwendet, um die schöne Sprache bereitzustellen.
“
RAG erweitert den Prompt, abhängig davon, worum es gerade geht, auf jeweils unterschiedliche Art. Es gibt dann nicht nur eine Liste von zehn verschiedenen Prompts, die besonders gut geeignet sind für, sagen wir, Mathematikfragen, sondern der Prompt wird ganz spezifisch für die Frage erweitert und verbessert mit Informationen, die hilfreich sein könnten, um die Frage zu beantworten.
„
Thomas Haschka: Genau, das oben genannte ist einer von vielen weiteren Anwendungsfällen. Derzeit ist es sehr beliebt, Informationen aus einem PDF herauszuholen. Sucht der User eine bestimmte Information in einer hundertseitigen Doktorarbeit, findet das LLM diese im bereitgestellten PDF und gibt hoffentlich eine Antwort mit den Daten aus dem Dokument heraus. So ist es möglich, Halluzinationen zu verhindern und nur mit den eigenen Daten zu arbeiten. Wer einen Chatbot für seine Webseite baut, kann sicher sein, dass der Chatbot nur Auskunft über die eigene Firma gibt und über sonst gar nichts.
Martin Pfister: Der Schritt von Prompt Engineering zu RAG ist ein natürlicher. Man könnte auch sagen, RAG ist Prompt Engineering on Steroids. Also das ist einfach nicht eine Art, eine Anfrage, die zum Prompt noch hinzugefügt wird, sondern RAG erweitert den Prompt, abhängig davon, worum es gerade geht, auf jeweils unterschiedliche Art. Und so gibt es dann nicht nur eine Liste von zehn verschiedenen Prompts, die besonders gut geeignet sind für, sagen wir, Mathematikfragen, sondern der Prompt wird ganz spezifisch für die Frage noch erweitert und verbessert mit Informationen, die hilfreich sein könnten, um die Frage zu beantworten.
Thomas Haschka: Als die LLMs aufgekommen sind, so um 2018, hatte man, glaube ich, gar nicht die Ahnung, was alles möglich ist. Und 2020 hat dann halt jemand gesagt, ich spiele jetzt mal externen Content in meinen Prompt ein.
Simeon Harrison: Beziehungsweise macht RAG erst dann Sinn, wenn das Modell auch eine bestimmte Sequenzgröße aufnehmen kann. Vor 2020 war die schon sehr begrenzt. Aber Large Language Models waren damals natürlich schon supernützlich, zum Beispiel um Kundenrezensionen auszuwerten. So ließ sich herausfinden, was die Leute über mein Produkt oder meine Marke sagen. Dafür waren LLMs top. Dass sie jetzt mit mir chatten oder viel Content ausgeben, das ist erst später dazu gekommen.
Thomas Haschka: Die Tools verändern sich ständig, sind also Teil eines aktiven Entwicklungsprozesses. Generell braucht es erst einmal ein trainiertes LLM, dann ein Embeddingmodel und eine Vektordatenbank, um schnell passende Informationen zur Anfrage zuliefern zu können.
Thomas Haschka: RAG kann firmeninterne Dokumente verarbeiten, auf die das LLM nicht trainiert wurde. Man erhält richtige Antworten, indem man das LLM zwingt, nur zu antworten, wenn die angefragten Informationen in den zugespielten Dokumenten enthalten sind. Es geht auch um Selbstreflektion über Chain-of-Thought, indem man die Antwort des LLMs selbst als Drittinformation in den Prompt einschleust und das LLM bittet, seine eigene Antwort zu beurteilen, bevor es antwortet.
“
Die Tools verändern sich ständig, sind also Teil eines aktiven Entwicklungsprozesses. Generell braucht es erst einmal ein trainiertes LLM, dann ein Embeddingmodel und eine Vektordatenbank, um schnell passende Informationen zur Anfrage zuliefern zu können.
„
Simeon Harrison: Wenn du eine bestimmte Fachsprache von deinem Modell haben willst, eine medizinische Sprache zum Beispiel oder eine juristische, dann wird RAG nicht mehr reichen. In diesem Fall wirst du ein feingetuntes Modell verwenden, aber das dann trotzdem in Kombination mit RAG einsetzen.
Thomas Haschka: Die Informationsbeschaffung ist oft sehr schwierig, und RAG kann wie gesagt das individuelle Training eines LLMs oder das Fine-Tuning oft nicht ersetzen. Zu beachten ist auch, welche Informationen man in den Prompt einspielt und wie man an diese Informationen kommt. Man muss jedenfalls das resultierende System testen, um sicher zu gehen, dass es die richtigen Informationen liefert, und dass auch die richtigen Informationen in den Prompt eingespielt wurden.
Ein großes Thema ist die Semantik. Das RAG-System sucht ähnliche Textstellen, die zur Anfrage passen. Es sucht also Wörter, die einander gleichen. Das System muss also zu jeder Frage irgendwie den richtigen Kontext finden. Dieser Prozess ist oft sehr mühsam. Nehmen wir das Beispiel, das wir vorher hatten: Du hast ein hundertseitiges PDF, eine Doktorarbeit. Und du willst wissen, was in Kapitel fünf steht. Die Frage ist, wie ich als RAG-Ersteller das semantisch löse. Denn „Kapitel eins“, „Kapitel zwei“ und „Kapitel drei“ klingen ähnlich wie „Kapitel fünf“. Vielleicht bekomme ich als Antwort zehn Mal die ersten zehn Zeilen von allen Kapiteln. Und woher weiß ich, welches von diesen Ergebnissen das richtige ist? Diese und weitere Fragen sind Teil der Forschung an RAG.
“
Wir Menschen erkennen den Unterschied zwischen den Aussagen „Ich gehe heute nicht ins Kino“ und „Ich gehe heute ins Kino“. Das LLM aber sieht beide als gleich an, was sie natürlich nicht sind. Das sind die Herausforderungen bei RAG. Insgesamt ist es ein aktiver Entwicklungsprozess.
„
Thomas Haschka: Über Embeddingmodelle. Aber die sind nicht immer perfekt.
Thomas Haschka: Ein Embeddingmodell ist eine Art Übersetzer, aber statt Wörter in eine andere Sprache zu übersetzen, übersetzt es Wörter oder Sätze in Zahlen. Heraus kommt eine Zahlencode, den ein Computer gut verstehen und vergleichen kann. Ein Embeddingmodell nimmt zum Beispiel den Satz „Der Hund läuft im Garten“ und verwandelt ihn in eine Zahlenliste aus, sagen wir, 300 Zahlen. Diese Zahlen nennt man Vektor. Sie enthalten die Bedeutung des Satzes. Ähnliche Sätze bekommen ähnliche Zahlenreihen, wie etwa der Satz „Ein Hund rennt draußen“. RAG nutzt Embeddings, um Texte zu finden, die zur Frage passen. Du fragst zum Beispiel: „Wie funktioniert ein Elektromotor?“. Das System wandelt die Frage in Zahlen um (bettet sie ein = embedding), sucht in einer Datenbank nach Dokumenten, deren Embeddings ähnlich sind und holt die passenden Texte heraus. Das LLM schreibt anhand der gefundenen Informationen schließlich die Antwort.
Hier liegt das große Problem, das ich vorhin schon erwähnt habe: Wir Menschen erkennen den Unterschied zwischen den Aussagen „Ich gehe heute nicht ins Kino“, „Ich gehe heute ins Kino“ oder „Ich bleibe heute zu Hause“. Für das LLM sind die beiden ersten Sätze ähnlicher als der erste und der dritte. Also wird fast jedes Embeddingmodell hier falsch liegen und sagen: „Ich gehe heute nicht ins Kino“ und „Ich gehe heute ins Kino“ gehören zusammen, was natürlich nicht stimmt; es sind zwei verschiedene Aussagen. Das sind die Herausforderungen bei RAG. Insgesamt ist es ein aktiver Entwicklungsprozess.
Thomas Haschka: Auf jeden Fall. Embedding wird in der Praxis großflächig verwendet und funktioniert gut genug, um Produkte zu bauen. Es ist nicht perfekt, aber es läuft.
Simeon Harrison: RAG ist sicher die nützlichste Methode für Unternehmen, um sich LLMs zunutze zu machen, weil sie damit zum Beispiel ihre Website-Chatbots und andere Dinge gut bauen können und es ein kostengünstiges Tool ist.
Lust darauf, mehr über RAG zu erfahren? EuroCC Austria bietet regelmäßig Trainings zu diesem und weiteren Themen an. Hier geht‘s zu den nächsten Kursen von EuroCC Austria/VSC.
Thomas Haschka
Thomas hat seinen Weg von der Simulation und Biophysik über Data Science hin zur künstlichen Intelligenz gefunden. Er promovierte in Frankreich und war in der Forschung am Musée National d'Histoire Naturelle, am Institut Pasteur sowie am Paris Brain Institute tätig. Bevor er an die TU Wien zurückkehrte, unterrichtete er über ein Jahr lang künstliche Intelligenz an der Amerikanischen Universität in Beirut. Bei der EuroCC-Austria-Trainingsreihe Foundations of LLM Mastery ist Thomas als Trainer für den Bereich RAG verantwortlich.
Martin Pfister
Martin hat an der TU Wien Physik studiert und dissertiert derzeit im Bereich der medizinischen Physik an der MedUni Wien. Bei EuroCC Austria unterstützt er Kund:innen dabei, ihre Projekte am österreichischen Supercomputer VSC abzuwickeln und unterrichtet zu den Themen Deep Learning/Machine Learning.
Simeon Harrison
Simeon ist Trainer bei EuroCC Austria und hat sich auf die Bereiche Deep Learning/Machine Learning spezialisiert. Der ehemalige Maschinenbauer und Mathematiklehrer erhält von den Teilnehmenden seiner Kurse Feedbacks wie: „Simeon Harrison ist ein exzellenter Trainer. Sein Unterrichtsstil ist klar, ansprechend und gut strukturiert, was das Lernen sehr angenehm macht.“


