Anyone training LLMs will quickly find themselves turning to GPU instances in the cloud. But there’s an alternative: supercomputers are more energy-efficient, offer better infrastructure for parallel training – and can even cost less. EuroCC experts Martin Pfister, Simeon Harrison and Thomas Haschka explain when the switch makes sense in this interview.
Bettina Benesch
Thomas Haschka: When working on a high-performance computing (HPC) cluster, certain tasks become easier because all computing units have access to the same data system. If you rent computing power in the cloud, the machines are usually networked together, but they still behave as individual computers rather than as a unified system where everything runs seamlessly.
Simeon Harrison: The Austrian supercomputers VSC-4 and VSC-5 consume significantly less energy compared to some cloud providers. This is due to the cooling system: Cloud providers often take a more relaxed approach to cooling because their servers are located in regions where energy is cheaper, and waste heat is not as big an issue as it is for us.
At VSC, the majority of energy is used for computation, with cooling requiring only about 10%. In the cloud, however, cooling can demand up to 100% of the computing power—one half for processing and the other half for keeping the system from overheating. That being said, some cloud providers prioritise green computing, although these services tend to be more expensive.
Martin Pfister: Cost is an argument in favour of an HPC system. Through the EuroCC project, businesses within the EU are currently eligible for free test access to European supercomputers. Supercomputers are particularly well suited for fine-tuning since the computational workload is intensive but finite—you put in a large computing effort once and end up with a fully fine-tuned model.
Thomas Haschka: In the cloud, you have to handle many things yourself. You usually have to build your own operating system image or Docker container. On a supercomputer, most of these are pre-installed.
Simeon Harrison: There’s also the fact that most people don’t have multiple GPUs at home. MUSICA, Austria’s latest high-performance computer, for example, has 272 compute nodes, each equipped with four GPUs—so in total, 1088 GPUs are available, along with additional CPU partitions. Supercomputing is therefore ideal for working with vast amounts of data.
“
Through the EuroCC project, businesses within the EU are currently eligible for free test access to European supercomputers.
„
Simeon Harrison: As soon as you realise that your system's memory is overloaded.
Martin Pfister: But it’s not always just about the amount of data; time is also an important factor. One of our clients is training a relatively small model. Technically, a supercomputer is far more powerful than what he actually needs. However, the Austrian supercomputer VSC enabled him to train 200 different models with varying parameters in parallel in a short time. This allowed him to optimise the model far more effectively than he could have done using just a single GPU.
Thomas Haschka: Certainly the legal sector, as well as medicine and any industry that requires LLM responses in a specialised language and cannot rely on open, pre-trained models.
Thomas Haschka: A supercomputer usually comes with more bureaucracy, and the process of getting access takes longer. Pre-installed software can also be a challenge, even though I mentioned it earlier as an advantage. Unlike the cloud, a supercomputer comes with a fixed set of software, compilers, and toolchains. If your Python version isn’t compatible with the system, installing additional dependencies can be difficult. Additionally, any code you run must be designed to operate across multiple compute nodes in parallel. That means your training code must be written in a way that takes full advantage of a supercomputer’s power, including the ability to distribute workloads across multiple machines.
“
After our training, participants will be able to fine-tune models that do not fit into the memory of a single GPU—whether on a laptop, a workstation, or even a single GPU on a supercomputer.
„
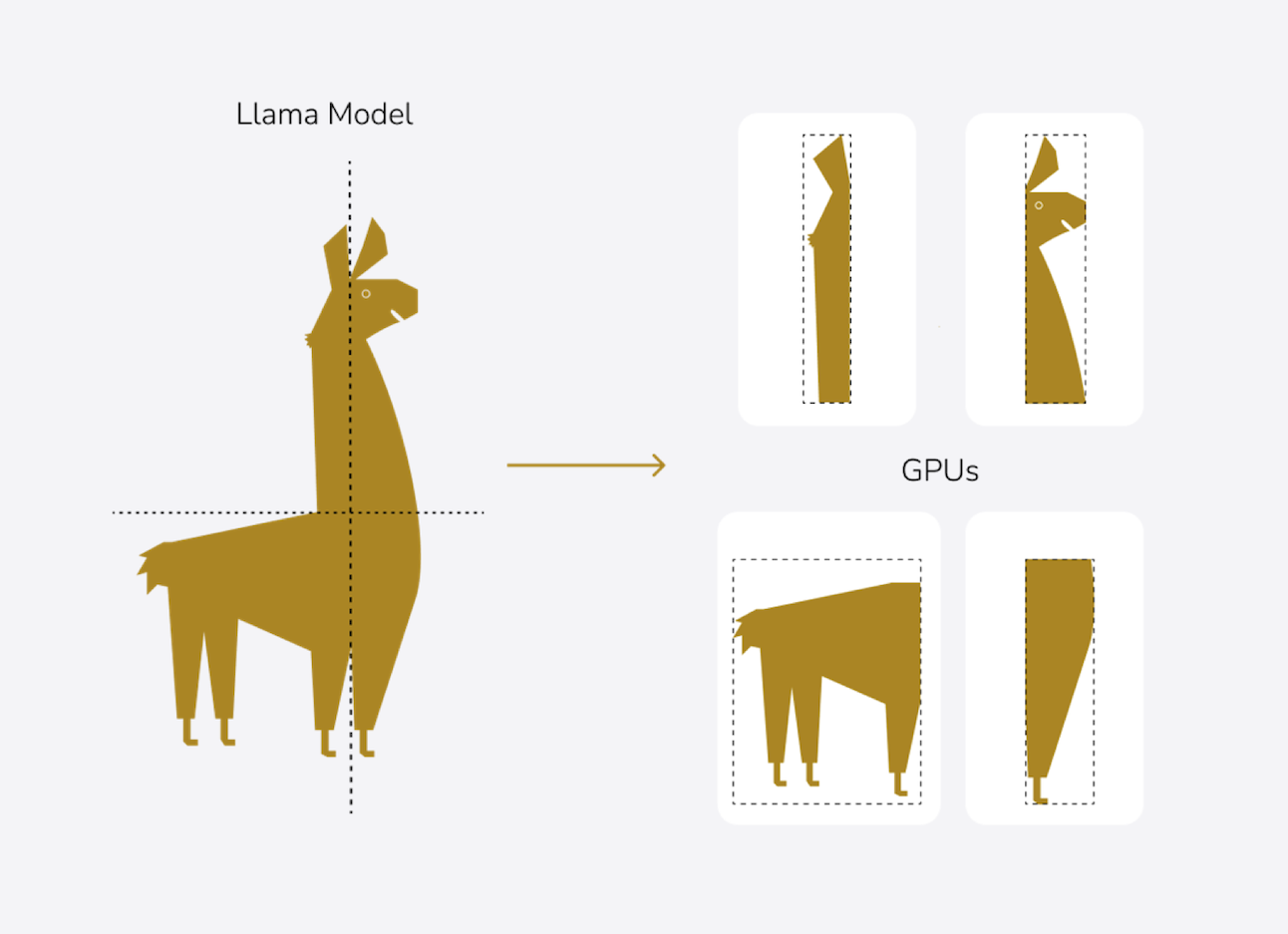
Simeon Harrison: We start with theory, using presentations. Then, we move into our Jupyter Notebooks, which allow us to combine code, text, images, and other content in a single document. This enables us to move quickly to hands-on examples. We go through the Jupyter Notebooks together, explain the code, and explore what can be discovered within it. After that, participants will do some coding themselves and experiment with different techniques. In the "Multi GPU" course, we focus on large models—one of them being Llama 3. The entire course will take place on LEONARDO, currently ranked ninth in the world for computing power.
Simeon Harrison: They will be able to fine-tune models that do not fit into the memory of a single GPU—whether on a laptop, a workstation, or even a single GPU on a supercomputer. We teach techniques where, for example, the model itself is split and distributed across multiple GPUs. This isn’t magic, but it’s also not entirely straightforward. You really need to see it done once—otherwise, you’ll find yourself stuck in an endless cycle of trial and error. Searching through documentation for the right answers to specific problems can take ages. We spent hundreds of hours figuring all this out so that others don’t have to.
Martin Pfister
Martin studied physics at TU Wien and is currently pursuing a doctorate in medical physics at MedUni Wien. At EuroCC Austria, he helps clients run projects on the Austrian VSC Supercomputer and teaches Deep Learning and Machine Learning.
Simeon Harrison
Simeon is a trainer at EuroCC Austria, specialising in Deep Learning and Machine Learning. A former mathematics teacher, he receives feedback from course participants such as: "Simeon Harrison is an excellent teacher. His teaching style is clear, engaging, and well-structured, making the topics more enjoyable to learn.”
Thomas Haschka
Thomas made his way from simulation and biophysics to data science and ultimately to artificial intelligence. He earned his PhD in France and conducted research at the Muséum National d'Histoire Naturelle, Institut Pasteur, and the Paris Brain Institute. Before returning to TU Wien, he spent over a year teaching artificial intelligence at the American University of Beirut. In the Foundations of LLM Mastery series, Thomas is responsible as a trainer for the RAG domain.



Austrian Scientific Computing regularly offers courses on high-performance computing, AI, and high-performance data science. See the current courses.
About the key concepts
Training an AI model requires various tools and approaches—even when using pre-trained models as a starting point. In our "Foundations of LLM Mastery" training series, we cover all the essential tools: Retrieval-Augmented Generation (RAG), Prompt Engineering, and Fine-tuning. These techniques are usually combined to optimise models iteratively, gradually refining them towards the best possible results.
Prompt Engineering
Anyone who works with large language models (LLMs) knows that the quality of the output depends on the quality of the prompt. Prompt engineering enhances user inputs by adding background instructions to provide the model with additional context, making responses more precise and better suited to the intended audience. For instance, if someone is training a chatbot for children, the prompt could include a directive like: "Answer the question in a child-friendly way. Avoid responding to topics such as war or violence, as these could be distressing for children."
Retrieval-Augmented Generation (RAG)
RAG allows an AI model to access an additional database to retrieve information. Imagine an employee asks their company’s internal system: "Can I take a half-day off?" The model would consult the database containing company policies on leave and respond: "Sorry, dear employee, but in this company, leave can only be taken in full-day increments." Since the model references validated and structured information, RAG helps prevent hallucinations and enables quick updates with new facts. RAG instructions are embedded within the system prompt, guiding the model to consider specific database information when formulating responses.
Fine-tuning
Fine-tuning is the process of refining a pre-trained model to adapt it to specific needs. Because supercomputers are highly suited for this task, we have prioritised fine-tuning as the first topic in our training series. In general, the fine-tuning process starts with a pre-trained LLM from Meta, Mistral, or another provider, which is then customised for a particular application. For example, a dataset of question-answer pairs could be used to teach the model a specific writing style. This is particularly important when training a model to understand and generate text in professional fields, such as medicine, where a specialised vocabulary is required. Fine-tuning is computationally intensive and is therefore ideal for running on a supercomputer.
For completeness: Training from Scratch
Training a large language model from scratch means building one from the ground up. This is rarely done nowadays, as there are already many strong pre-trained models available. However, for some languages or domains, no suitable model exists. A few years ago, there was no comprehensive LLM for all Nordic languages. This led to the development of Viking 7B, a model trained entirely from scratch on LUMI, Europe’s most powerful supercomputer. Similarly, for Arabic languages, the JAIS-7B model was created using the same approach.
Austrian Scientific Computing (ASC) – formerly known as the Vienna Scientific Cluster (VSC) – is a collaboration of several Austrian universities that provides supercomputer resources and technical support to their users.
The current flagship systems, VSC-4 and VSC-5, are the fastest supercomputers in Austria. They power advanced research and innovation in fields such as physics, chemistry, climate science, life sciences, engineering, and beyond.