Fine-tuning von LLMs auf multi GPUs
Fine-tuning von LLMs auf multi GPUs: Vor- und Nachteile eines Supercomputers
Wer LLMs trainiert, landet schnell bei GPU-Instanzen in der Cloud. Doch es gibt eine Alternative: Supercomputer sind energieeffizienter, bieten bessere Infrastruktur für paralleles Training, und kosten unter Umständen sogar weniger. Wann sich der Umstieg lohnt, erklären die EuroCC-Experten Martin Pfister, SImeon Harrison und Thomas Haschka im Interview.
Das Interview führte Bettina Benesch
LLMs auf der Cloud finezutunen ist längst nichts Besonderes mehr. Doch Supercomputer haben einige Vorteile gegenüber ihrem wolkigen Pendant. Welche sind das genau?
Thomas Haschka: Wer auf einem Cluster für High-Performance Computing (HPC) rechnet, tut sich bei gewissen Dingen leichter, weil alle Recheneinheiten Zugriff auf dasselbe Datensystem haben. Mietet man in der Cloud Rechner an, dann sind sie meistens zwar schon miteinander verbunden und haben auch ein gemeinsames Netzwerk, dennoch verhalten sie sich wie einzelne Rechner und nicht wie ein Rechensystem, in dem alles gemeinsam läuft.
Simeon Harrison: Die österreichischen Supercomputer VSC-4 und VSC-5 verbrauchen im Vergleich zu manchen Cloud-Anbietern deutlich weniger Energie. Der Grund liegt an der Art der Kühlung: Cloud-Provider gehen oftmals eher leger mit dem Thema um, denn ihre Server befinden sich mitunter an Standorten, wo Energie günstiger ist und die Abwärme keine derart große Rolle spielt wie bei uns.
Am VSC wird hauptsächlich für das Rechnen Energie aufgewendet; die Kühlung braucht zusätzlich nur etwa zehn Prozent. Bei der Cloud sind es bis zu hundert Prozent: Ein Teil fürs Rechnen und der gleiche Teil für die Kühlung. Allerdings gibt es auch Cloud-Anbieter, die auf Green Computing setzten, und dementsprechend meist teurere Systeme zu Verfügung stellen.
Martin Pfister: Die Kosten sind natürlich auch ein Argument für ein HPC-System: Im Rahmen des Projekts EuroCC ist ein erstes, umfangreiches Testrechnen auf einem europäischen Supercomputer derzeit kostenlos für Unternehmen im EU-Raum. Und gerade wenn es um Fine-tuning geht, eignet sich ein Supercomputer perfekt, weil man einmal einen großen Rechenaufwand hat und am Ende das fertig feineingestellte Modell.
Thomas Haschka: In der Cloud muss man viele Dinge selbst machen: Man muss sich meistens sein Betriebssystem-Image oder ein Docker-Image bauen. Auf einem Supercomputer sind all diese Dinge meistens schon vorinstalliert.
Simeon Harrison: Dazu kommt natürlich, dass man zu Hause für gewöhnlich nicht mehrere GPUs, also Grafikkartenprozessoren, zur Verfügung hat. MUSICA, der neueste Hochleistungsrechner in Österreich hat zum Beispiel 272 Rechenknoten mit jeweils vier GPUs, also insgesamt 1.088 sehr schnelle GPUs; und zusätzlich weitere CPU-Partitionen. Supercomputing eignet sich also für richtig große Datenmengen.
“
Im Rahmen des Projekts EuroCC ist ein erstes, umfangreiches Testrechnen auf einem europäischen Supercomputer derzeit kostenlos für Unternehmen im EU-Raum.
„
Von welchen Datenmengen sprechen wir? Ab wann macht ein HPC-System Sinn?
Simeon Harrison: Sobald man merkt, dass der Arbeitsspeicher explodiert.
Martin Pfister: Aber es geht nicht immer nur um die Datenmenge, sondern oft auch um Zeit: Einer unserer Kunden trainiert ein kleines Model. Eigentlich sind die Ressourcen am Supercomputer viel zu groß für das, was er braucht. Der VSC hat ihm aber ermöglicht, 200 Modelle mit unterschiedlichen Parametern innerhalb kurzer Zeit parallel zu trainieren. So konnte er das Modell besser optimieren als er es mit einer einzelnen GPU hätte machen können.
Gibt es Branchen, die von Fine-tuning auf einem Supercomputer besonders profitieren?
Thomas Haschka: Da ist sicher die Justiz oder das Rechtswesen dabei; die Medizin und alle Industrien, die Antworten von LLMs in ihrer Fachsprache benötigen, und auf offene, bereits trainierte LLMs nicht zurückgreifen können.
Wir haben viel über die Vorteile von HPC gehört. Was sind denn die Herausforderungen beim Arbeiten mit einem Supercomputer?
Thomas Haschka: Man hat bei einem Supercomputer meistens mehr Bürokratie und wartet etwas länger auf einen Zugang. Man könnte auch die vorinstallierte Software als Herausforderung bezeichnen – auch wenn ich sie weiter oben als Vorteil genannt habe: Im Vergleich zur Cloud ist auf einem Supercomputer eine gewisse Software, ein Compiler oder eine Tool-Chain immer schon an Board. Wer da nicht die Python-Versionen hat, die auf diesem Supercomputer laufen, tut sich schwerer, Software nachträglich zu installieren und das System an seine Bedürfnisse anzupassen. Und es braucht immer auch den Code, der auf mehreren Rechenknoten parallel läuft. Das heißt: Der Trainingscode muss so geschrieben sein, dass er den Vorteil eines Supercomputers auch ausschöpfen kann, nämlich die Verbindung der einzelnen Rechner und damit die große Rechenleistung.
“
Nach unserem Kurs können die Teilnehmenden LLM-Modelle fine-tunen, die nicht im Speicher einer GPU Platz haben, weder auf der eines Laptops noch der eigenen Workstation, und auch nicht auf einer einzigen GPU eines Supercomputers.
„
Lasst uns noch über das Training an sich reden: Was dürfen sich eure Teilnehmer:innen von Kursen erwarten, wie etwa dem zu Fine-tuning on multi GPU?
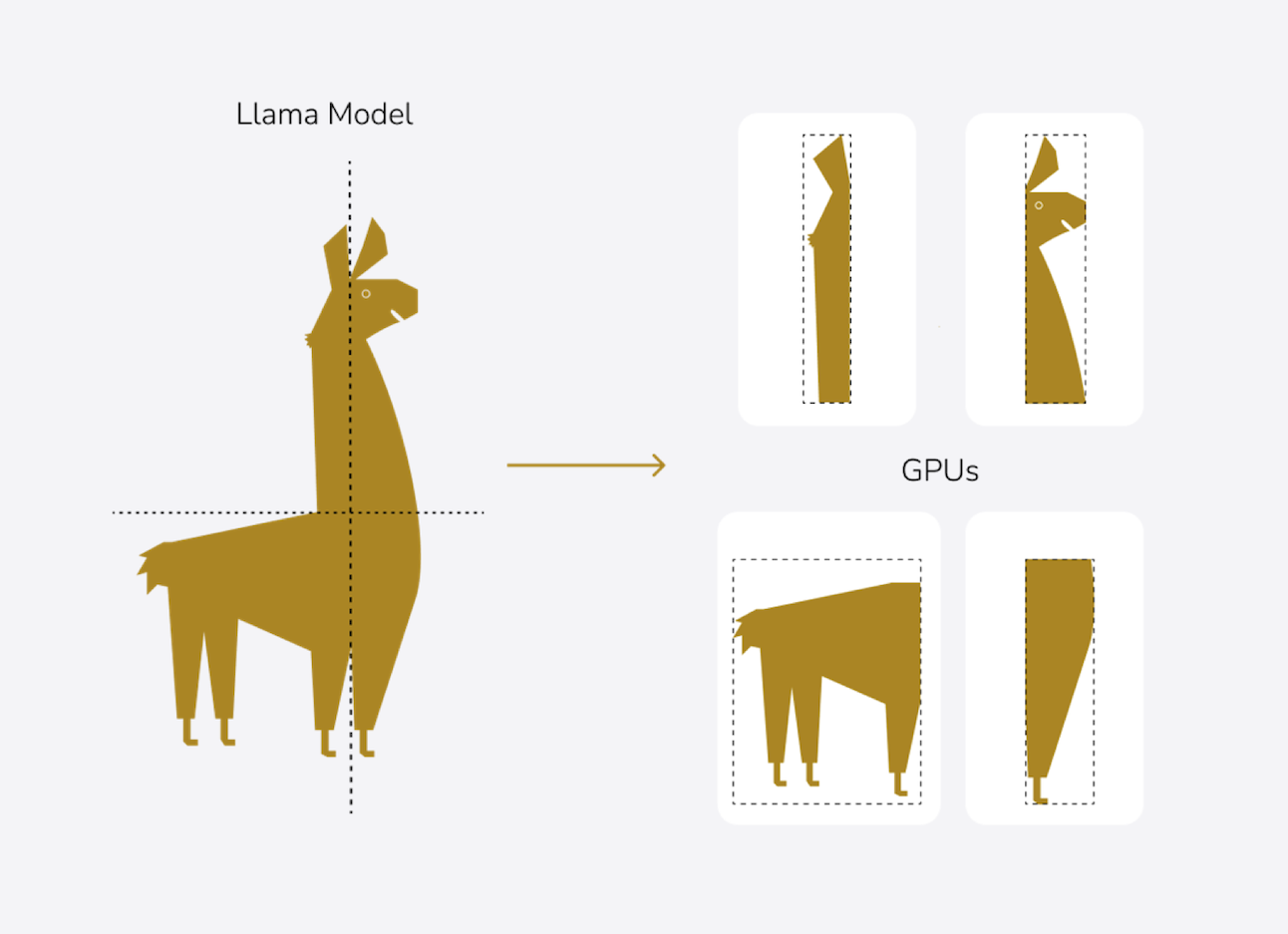
Simeon Harrison: Bei diesem erwähnten Kurs fangen wir ganz klassisch mit Theorie an, in Form von Präsentationen. Danach springen wir in unsere Jupyter Notebooks, die es ermöglichen, Code- und Text-Teile oder auch Bilder und andere Inhalte in einem einzigen Dokument zu kombinieren. So können wir sehr rasch mit praktischen Beispielen starten. Das heißt, wir gehen gemeinsam durch die Jupyter Notebooks und erklären dort den Code und was sich darin entdecken lässt. Anschließend programmieren die Teilnehmenden selbst ein bisschen und können Verschiedenes ausprobieren. Im Kurs „Multi GPU“ konzentrieren wir uns auf große Modelle, und eines davon ist zum Beispiel Llama 3.
Was können die Leute nach dem Kurs, was sie vorher nicht konnten?
Simeon Harrison: Sie können Modelle fine-tunen, die nicht im Speicher einer GPU Platz haben, weder auf der eines Laptops noch der eigenen Workstation, und auch nicht auf einer einzigen GPU eines Supercomputers. Wir zeigen ihnen Techniken, bei denen zum Beispiel das Modell selbst aufgesplittet wird und verteilt gerechnet werden kann. Das ist keine Hexerei – aber auch nicht ganz trivial. Man muss es einfach mal gezeigt bekommen, weil man sonst in einer Endlosschleife von Trial and Error landet. Denn wer die Dokumentation absucht, um gute Antworten zu gewissen Dingen zu bekommen, sucht sehr lange. Wir haben uns das in vielen Stunden erarbeitet und machen diesen Kurs nun, damit sich andere nicht so quälen müssen.
Ihre Trainer
Martin Pfister
Martin hat an der TU Wien Physik studiert und dissertiert derzeit im Bereich der medizinischen Physik an der MedUni Wien. Bei EuroCC Austria unterstützt er Kund:innen dabei, ihre Projekte am österreichischen Supercomputer VSC abzuwickeln und unterrichtet zu den Themen Deep Learning/Machine Learning.
Simeon Harrison
Simeon ist Trainer bei EuroCC Austria und hat sich auf die Bereiche Deep Learning/Machine Learning spezialisiert. Der ehemalige Mathematiklehrer erhält von den Teilnehmenden seiner Kurse Feedbacks wie: „Simeon Harrison ist ein exzellenter Trainer. Sein Unterrichtsstil ist klar, ansprechend und gut strukturiert, was das Lernen sehr angenehm macht.“
Thomas Haschka
Thomas hat seinen Weg von der Simulation und Biophysik über Data Science hin zur künstlichen Intelligenz gefunden. Er promovierte in Frankreich und war in der Forschung am Musée National d'Histoire Naturelle, am Institut Pasteur sowie am Paris Brain Institute tätig. Bevor er an die TU Wien zurückkehrte, unterrichtete er über ein Jahr lang künstliche Intelligenz an der Amerikanischen Universität in Beirut. Bei der Reihe Foundations of LLM Mastery ist Thomas als Trainer für den Bereich RAG verantwortlich.



Die Kurse des ASC
Austrian Scientific Computing bietet laufend Kurse zu den Themen High-Performance Computing, KI und High-Performance Data Science an. Zu den aktuellen Kursen.
Die wichtigsten Begriffe kurz erklärt
Ein KI-Modell zu trainieren bedarf verschiedener Tools und Ansätze – selbst dann, wenn fix-fertige Modelle als Ausgangsbasis dienen. In unserer Trainings-Reihe „Foundations of LLM Mastery” widmen wir uns allen wichtigen Werkzeugen: RAG, Prompt Engineering und Fine-tuning. Sie werden in der Regel miteinander kombiniert, um das Modell immer weiter zu optimieren. Das geschieht meist iterativ, man nähert sich also schrittweise und in wiederholten Schleifen der optimalen Lösung.
Prompt Engineering
Jeder Mensch, der als Anwender:in mit Large Language Models (LLM) arbeitet, kennt das Prompten und weiß: Die Antwort ist immer nur so gut wie mein Prompt. Prompt Engineering ergänzt die Eingaben der Anwender:innen mit solchen aus dem Hintergrund, um dem Modell weitere Informationen zu geben, damit die Antworten präziser sind und zu den Anwender:innen passen. Wer zum Beispiel einen Chat-Bot für Kinder trainieren möchte, wird den Prompts so etwas anfügen wie „Beantworte die Frage kindgerecht. Verzichte auf eine Antwort bei Themen wie Krieg/Gewalt etc., die Kinder verstören könnte“.
RAG: Retrieval Augmented Generation
RAG dient dazu, dem KI-Modell eine zusätzliche Datenbank zur Verfügung zu stellen, aus der es Informationen ziehen kann. Nehmen wir als Beispiel eine Anfrage eines Mitarbeiters an das unternehmenseigene System: Er möchte einen halben Tag Urlaub nehmen und fragt, ob das möglich ist. Das Modell greift auf die Datenbank zu, in der alles über Urlaubsansprüche zusammengefasst ist, und antwortet: Sorry lieber Mitarbeiter, in diesem Unternehmen kannst du dir nur ganze Arbeitstage frei nehmen. Weil das Modell auf konkrete und validierte Informationen zurückgreift, hilft RAG, Halluzinationen zu vermeiden, und es lassen sich auch schnell neue Informationen einspeisen. RAG fließt in den System-Prompt mit ein: Es ist die Aufforderung an das Modell, unter gewissen Gegebenheiten die Informationen aus der Datenbank zu berücksichtigen.
Fine-tuning
Hier geht es um den letzten Schliff. Weil sich Supercomputer für diese Aufgabe besonders gut eignen, haben wir diesen Part vorgezogen und bringen ihn in unserer Trainings-Reihe zeitlich als erstes. Basis des Fine-tunings ist ein vortrainiertes LLM von Meta, Mistral oder einem anderen Anbieter, das für die eigenen Bedürfnisse feineingestellt wird. Das Modell erhält zum Beispiel einen Datensatz mit Frage-Antwort-Paaren, sodass es eine bestimmte Ausdrucksweise lernen kann. Das ist unter anderem dann notwendig, wenn ein Modell z. B. für Mediziner:innen in deren Fachsprache trainiert werden soll. Fine-tuning ist sehr rechenaufwändig und eignet sich daher ideal, um auf einem Supercomputer zu laufen.
Zu guter Letzt und der Vollständigkeit halber noch Training from scratch
Training from scratch bedeutet, ein KI-Modell von Grund auf selbst zu bauen. Das passiert inzwischen so gut wie nie, weil reichlich vortrainierte Modelle existieren. Allerdings gibt es für einige Bereiche nichts Fertiges. Vor einigen Jahren fehlte beispielsweise in LLM für alle nordischen Sprachen. Durch Training from scratch entstand das LLM Viking 7B, das auf Europas leistungsstärkstem Supercomputer LUMI von null weg trainiert wurde. Auch für die arabischen Sprachen gibt es zum Beispiel mit JAIS-7B einen solchen Ansatz.
ASC (Austrian Scientific Computing) – ehemals Vienna Scientific Cluster (VSC) – ist ein Zusammenschluss mehrerer österreichischer Universitäten, der Supercomputing-Ressourcen sowie technischen Support für deren Nutzer:innen bereitstellt.
Die derzeitigen Flaggschiffe, VSC-4 und VSC-5, sind die leistungsstärksten Supercomputer Österreichs. Sie treiben Spitzenforschung und Innovation voran, unter anderem in Physik, Chemie, Klimaforschung, Lebenswissenschaften und Ingenieurwesen.