The AI that knows when shadows arrive
The AI that knows when shadows arrive
It’s not just us craving sunshine these days: operators of photovoltaic systems are also eagerly awaiting every ray of light. At the same time, they want to be able to plan the productive hours of their systems. To meet this need, the Vienna-based software developer LuxActive has created the world’s first AI tool for shadow prediction: CloudShadingAI forecasts shadow movements with an accuracy of up to 95 per cent. The project received technical support from Austria’s competence centre for supercomputing, while funding was provided by the Austrian Research Promotion Agency (FFG).
Bettina Benesch
Renewable energy is only as good as the conditions it operates under, and operators of photovoltaic systems want to ensure their installations are located where renewable energy can be generated most efficiently. Knowing where and when shadows will occur makes planning much easier. With CloudShadingAI, such a planning tool is now available. It was trained by the Vienna-based IT company LuxActive in partnership with MetGIS, a spin-off from the University of Vienna that produces global high-precision weather forecasts. The system provides predictions for both cloud shadows and terrain shadows (e.g. from mountains).
The tool is based on data describing the shape and elevation of the Earth’s surface (so-called terrain data), satellite cloud data, and meteorological weather data, and is already fully operational. Terrain shadows can already be viewed free of charge for three days into the future and past via https://shadow.swisdata.eu. Cloud shadow forecasts are available to companies for a fee.

CloudShadingAI can predict shadows for a time horizon ranging from 15 minutes to six hours. Accuracy is already very high for forecasts up to four hours ahead – the further into the future the prediction extends, the more difficult it becomes, as clouds are inherently unpredictable. Nevertheless, the accuracy of CloudShadingAI is significant: extrapolated over a year, it stands at 83 per cent, while the average for one month (January 2023) is 95 per cent.
Computation time reduced by around 93 per cent thanks to EuroCC Austria
EuroCC Austria, the Austrian competence centre for supercomputing, supported LuxActive with consulting and access to high-performance computing (HPC). The team trained multiple AI models on the Italian supercomputer Leonardo, one of the most powerful systems in the world. EuroCC assisted with onboarding onto the HPC system and provided expertise and tutorials throughout the project.
By working on the supercomputer, LuxActive’s team was able to significantly reduce computation time: training all 67 AI models took around 24 hours. On a local machine, the process would have taken two weeks. Leonardo thus achieved a reduction of 93 per cent. The model is now in operation, running on LuxActive’s own hardware and delivering predictions in just five to fifteen minutes.
“
The huge advantage of Leonardo is that you can run not just a single training job, but several in parallel, each on its own GPU. That simply wouldn’t have been possible locally.
„
The advantage of a high-performance computer lies in the computational space it provides, making it ideal for experimentation – comparable to a football pitch where several teams can train simultaneously and test which combinations are most efficient. An HPC system enables large-scale experimentation: “The huge advantage of Leonardo is that you can run not just a single training job, but several in parallel, each on its own GPU,” says LuxActive developer Fabian Frauenberger. “That simply wouldn’t have been possible locally. We would have had to run one job after another. On Leonardo, we could run several at once, allowing us to experiment much faster and reach good results far more quickly.”
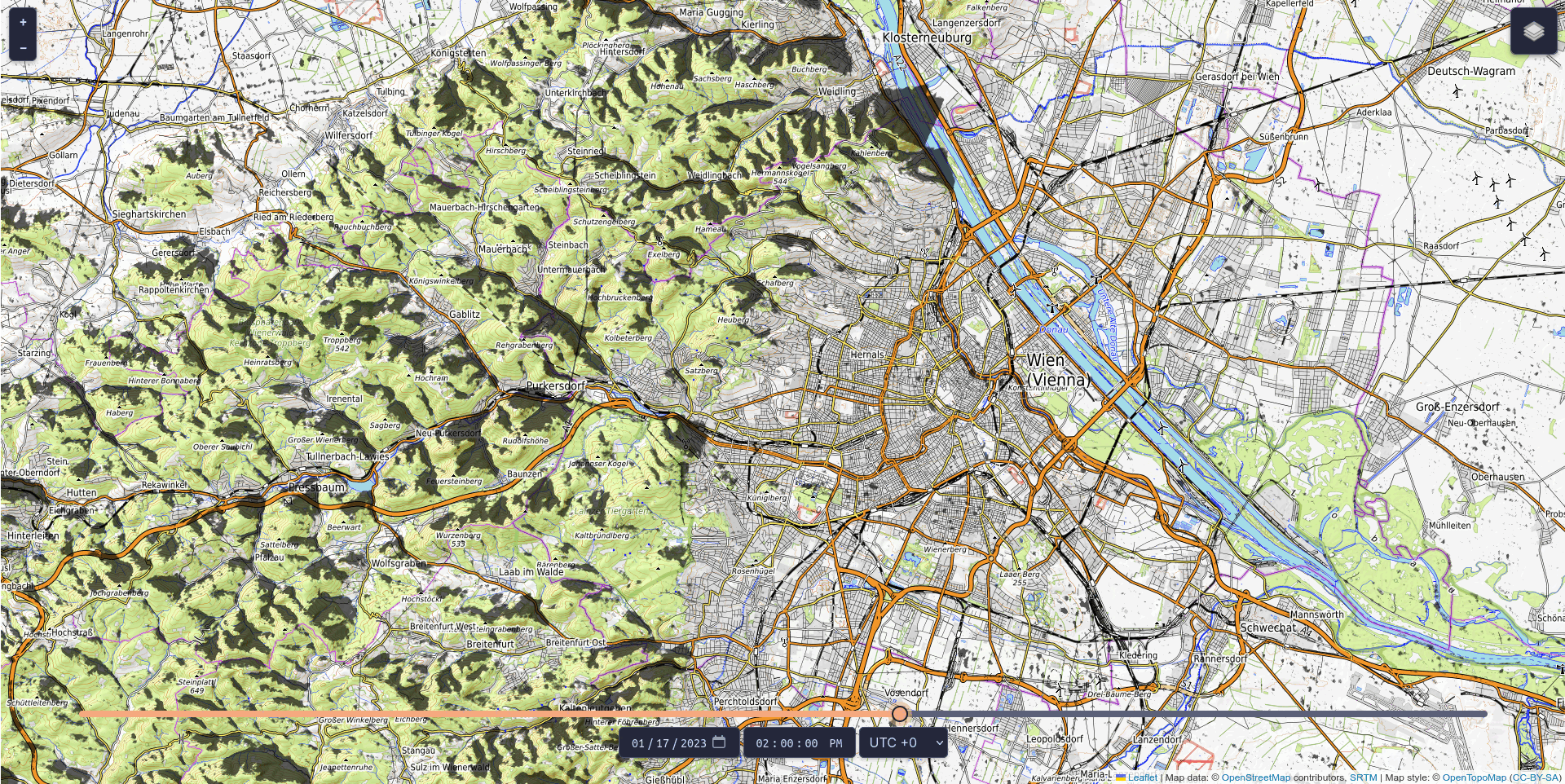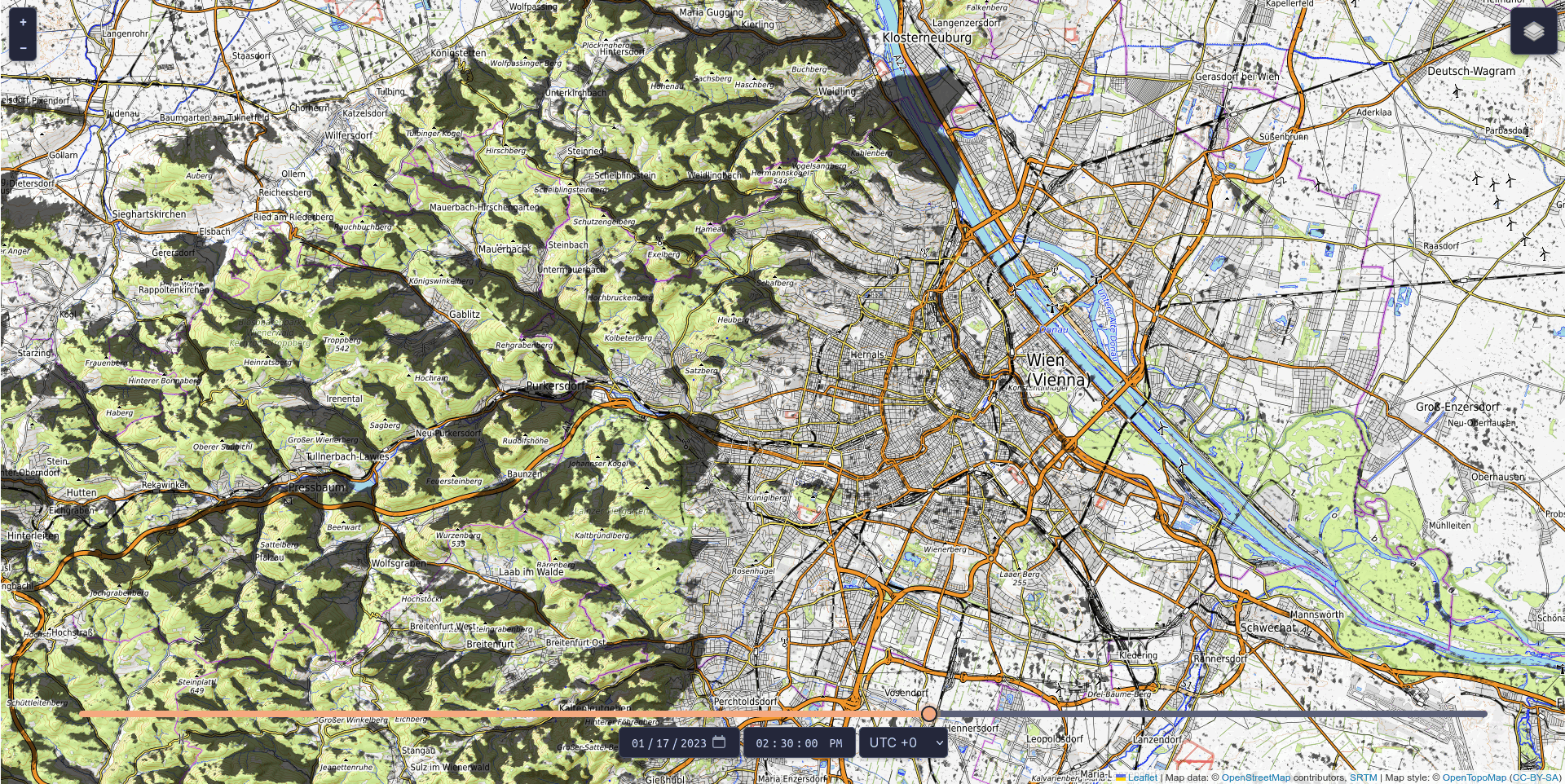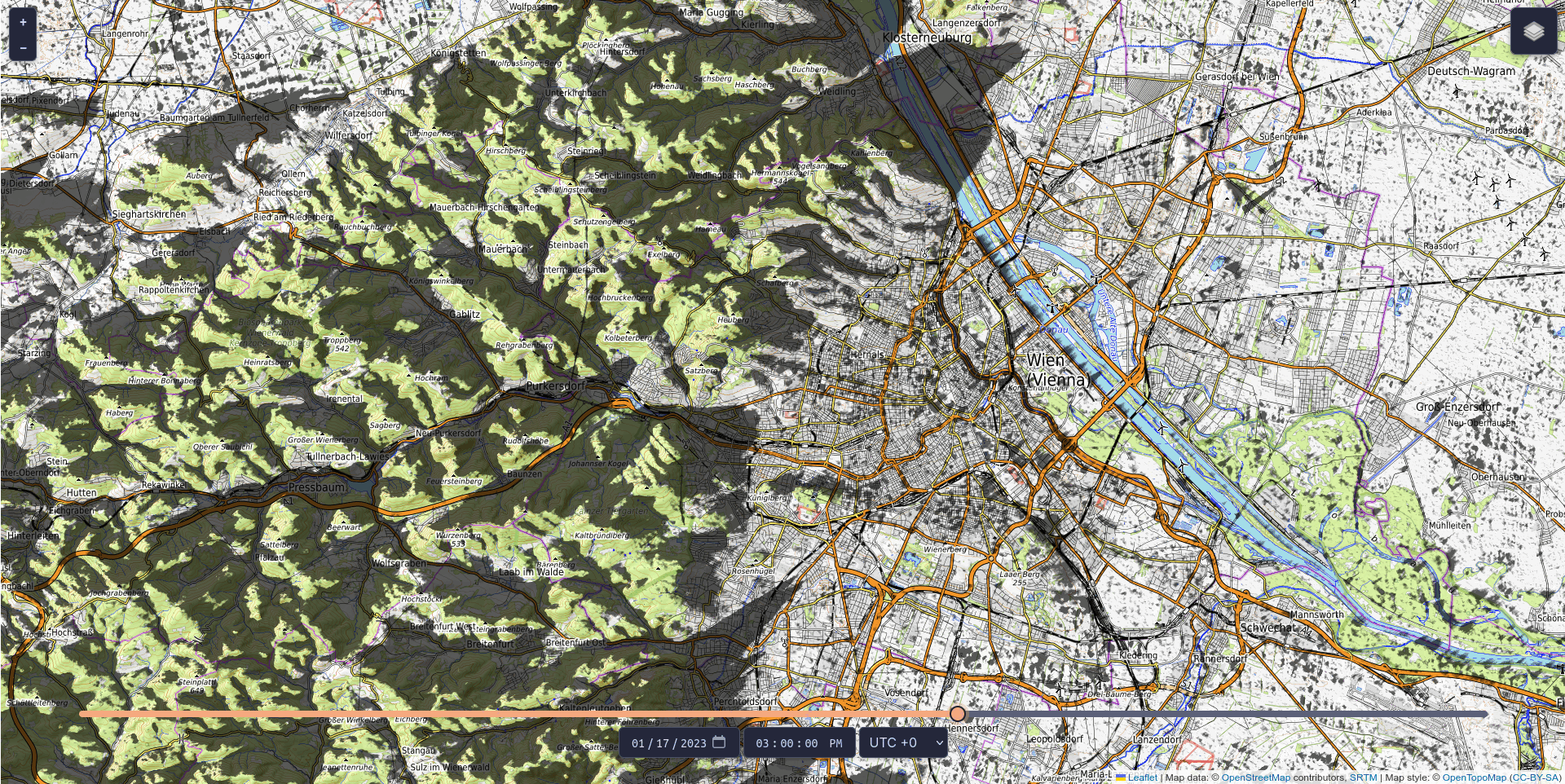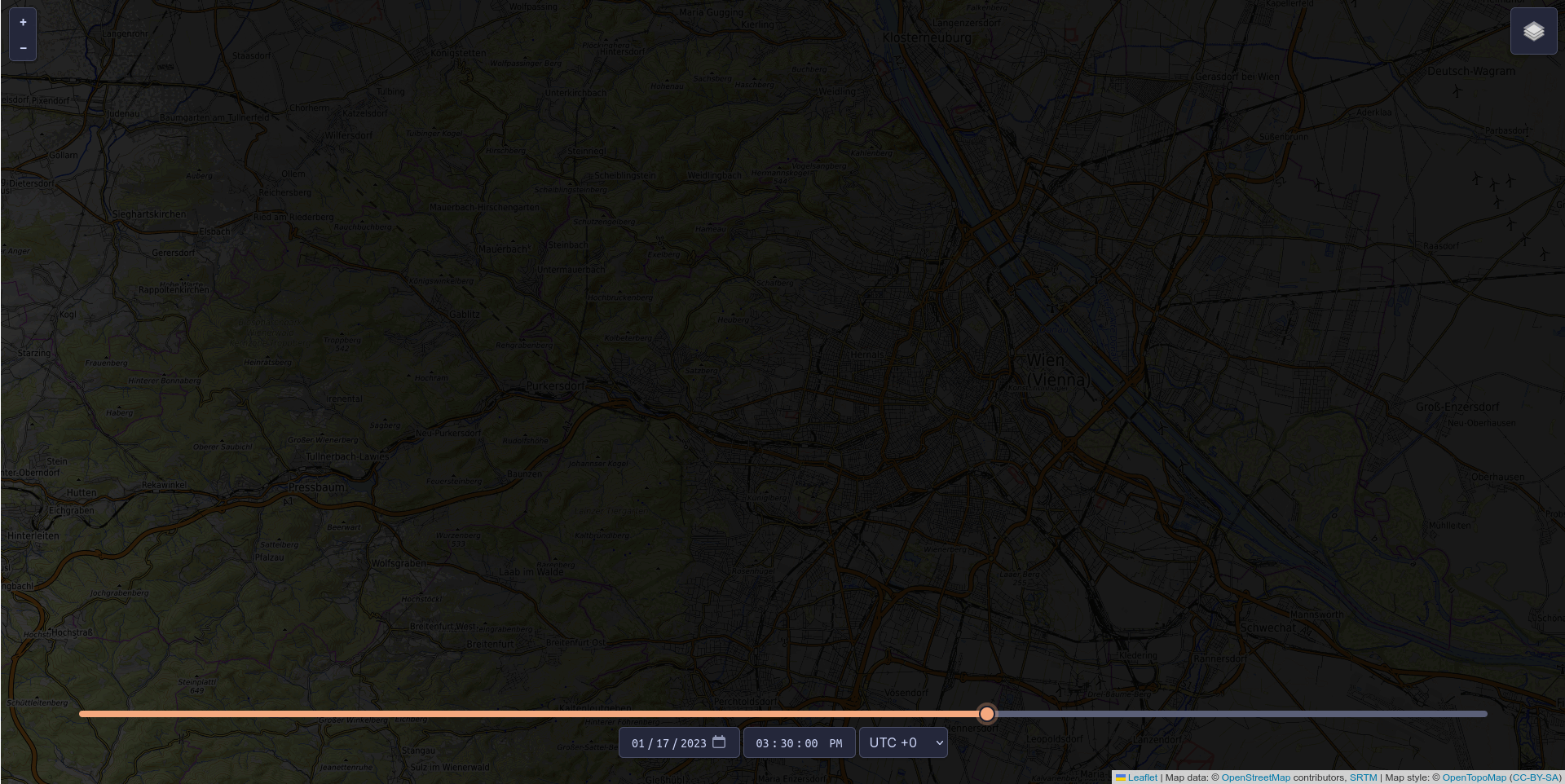
© Fabian Frauenberger, LuxActive
Interview
The pitfalls of doing something for the first time
Our author Bettina Benesch spoke with Fabian Frauenberger, one of the developers of CloudShadingAI, about the challenges, setbacks, and successes encountered during the project.
Dear Fabian, success stories like this often focus on what went well. But the real interest lies in the challenges and how they were overcome. What comes to mind?
Fabian Frauenberger: There were quite a few challenges. To develop our model, we used various data sources, including terrain data from one provider, which delivers the elevation of all features on the Earth's surface relative to sea level. You get longitude and latitude, along with the height of objects.
Interestingly, some lakes had incorrectly encoded elevations – about ten to twenty metres higher than their surroundings – which resulted in some lakes casting shadows onto mountains. This happens because water is assigned an incorrect value, while nearby objects lie below that value. The algorithm then assumes a shadow is being cast. We subsequently switched to a different dataset and the problem was resolved.
What were your challenges with cloud predictions?
Our main issue was the motion vectors we need to determine the direction in which clouds are moving. These vectors are at the core of CloudShadingAI and must be calculated precisely. Our first approach in training the AI was to feed the model only weather data and images and have it directly output the next image – effectively applying the motion vectors implicitly. That didn’t work at all. The only outputs were “there is always a cloud here” or “there is never a cloud here,” which obviously doesn’t reflect reality.
“
Our main problem was the motion vectors we need to determine the direction in which clouds move. Two approaches did not work. In the end, we tried our own method and compared individual pixels in the current image with similar pixels in a future image. This approach proved successful.
„
We then looked at how others calculate motion vectors and came across optical flow algorithms, where an input and an output image are provided and the model calculates the transformation between them. That didn’t work either.
Finally, we tried our own approach, comparing individual pixels in the current image with similar pixels in a future image (based on the surrounding pixel context). We used wind data to narrow down the area in which to search for similar pixels – this is known as targeting. This way, the model doesn’t have to search everywhere, only where the wind is likely to have carried the cloud. We then selected the best visual match among these candidates – a process known as scoring: which pixel best matches the original in terms of position and surroundings? This approach worked, and we were very relieved when it finally succeeded.
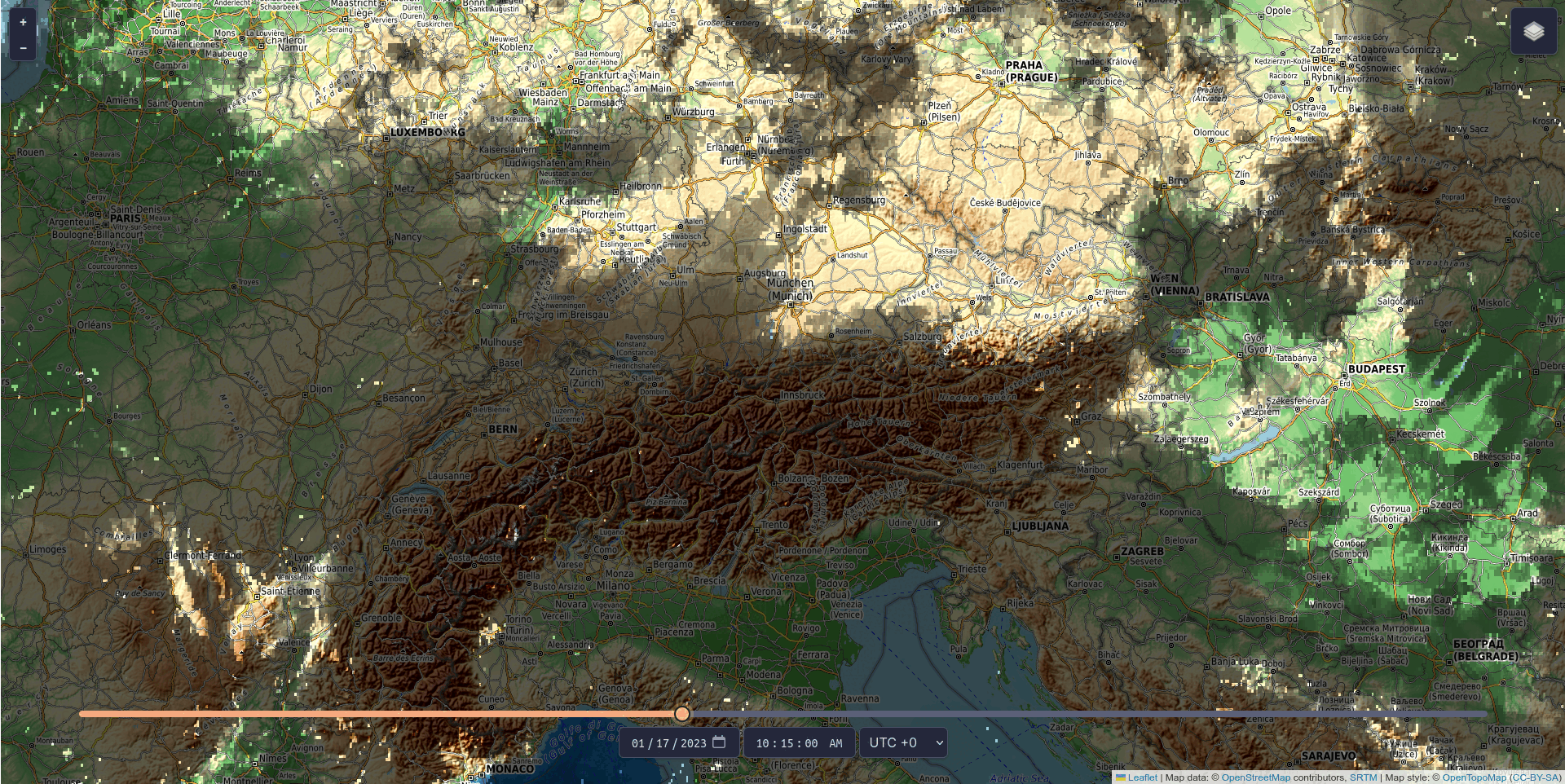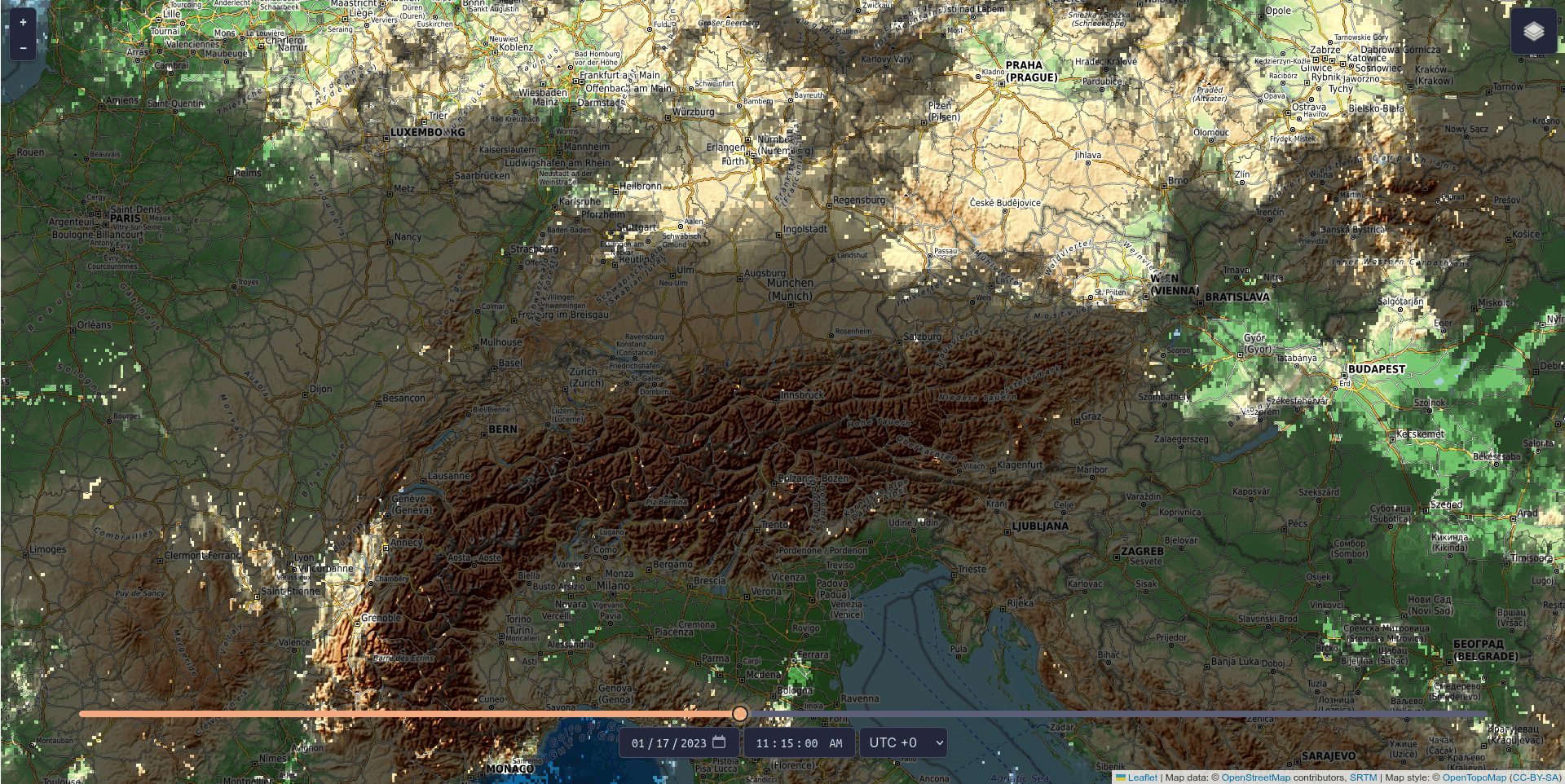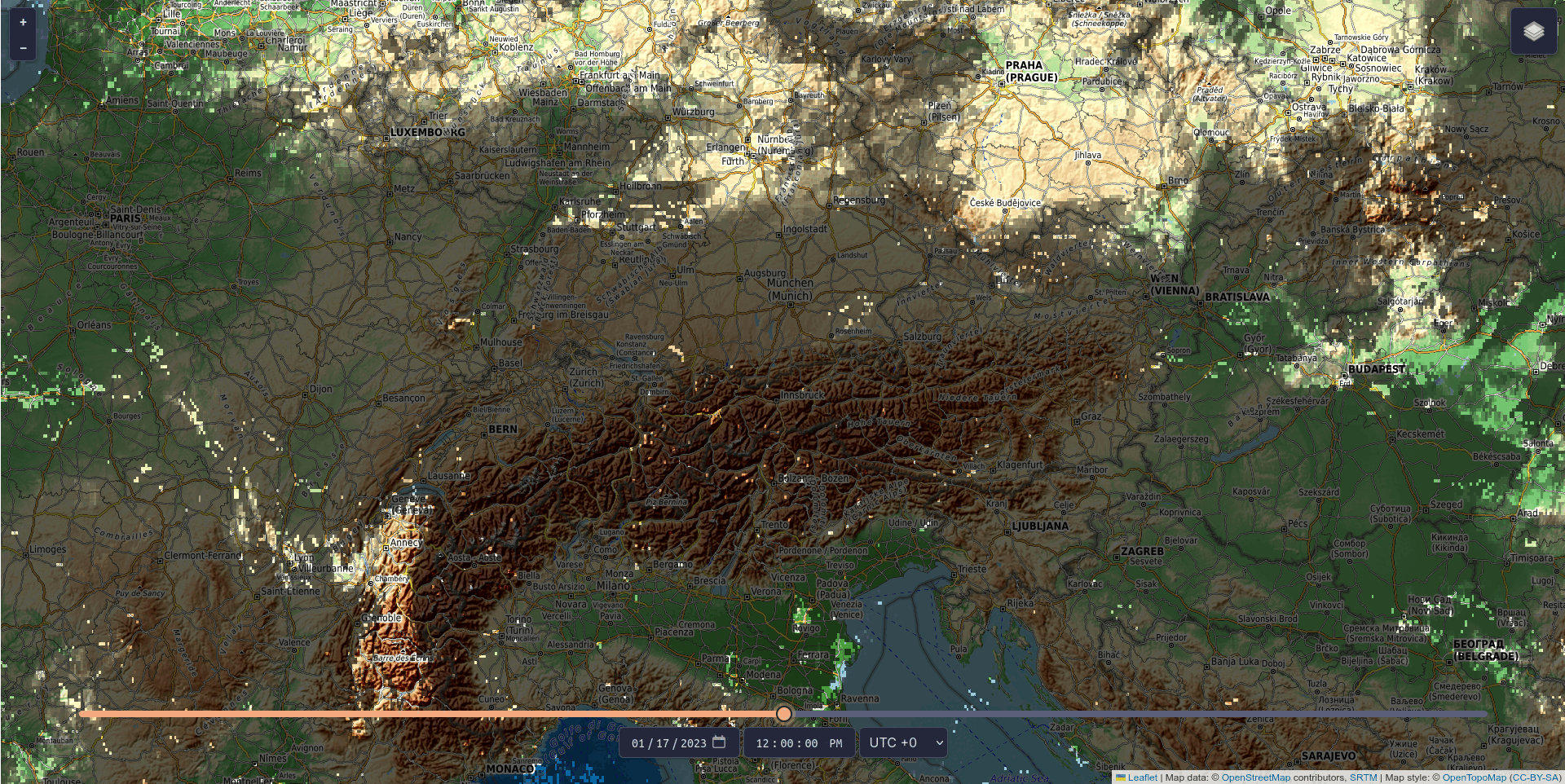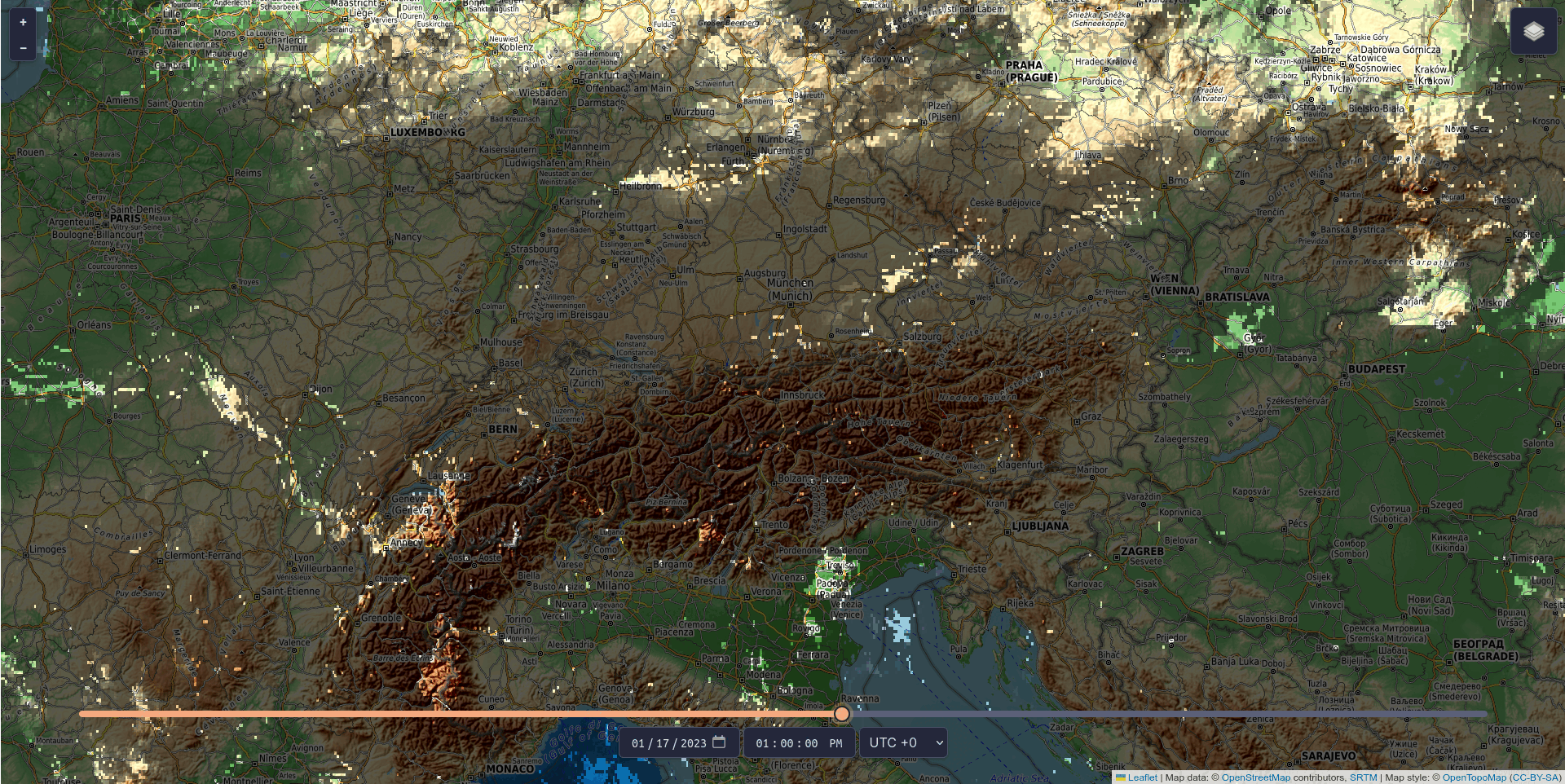
© Fabian Frauenberger, LuxActive
How long did it take to find the right approach for the motion vectors?
There were four of us working on it for three to four months – so quite a long time.
Were there any other hurdles?
Yes, cloud height was also an issue. We could only estimate it based on the available data. To explain: a cloud image isn’t like a picture of a cotton ball; it consists of data in which cloud height is encoded. Over Europe, we work with a grid of 1,200 by 1,200 pixels, where one pixel corresponds to 0.03 degrees of longitude or latitude. For each pixel, we receive information such as: there is a cloud here at a given height.
“
The problem is that we only know the highest point of the cloud; we do not know how deep it is. This cannot be measured. Therefore, it has to be determined in another way.
„
Why is height relevant?
A higher cloud casts its shadow further than a lower one. The problem is that we only know the highest point of the cloud, not its vertical extent. That cannot be measured directly, so it has to be inferred. We initially tried using meteorological data, assuming that high humidity would indicate the presence of a cloud – but that wasn’t reliable. Another idea was to determine it using AI, but we lacked sufficient ground-truth data, which would have been required. That’s something we may revisit in future projects.
In the end, we estimated cloud height by assigning a base height of 200 metres to each cloud and analysing its surroundings. For example, if one cloud is at 1,300 metres and a neighbouring one at 1,150 metres, we assume that the lower cloud also extends further downward.
And with that, the challenges were solved?
No, there were a few more. For example, we had issues with integer handling in PyTorch. Wind data also posed a challenge at one point, as it was given in metres per second and had to be converted into pixel units. Early on, we also realised that certain data are affected by the curvature of the Earth, which we needed to account for. Due to this curvature, distant clouds appear visually lower, which can cause the calculated shadow to be placed incorrectly.
We implemented terrain shadow calculations on the GPU, as it allows many computations to run in parallel. But even there, the graphics card surprised us: it approximated sine and cosine values, which led to odd artefacts in the shadows that we then had to painstakingly correct. Compared to the motion vector problem, however, these were minor issues.
“
There were a few other challenges as well. For example, we encountered issues with integer handling in PyTorch. And right from the start, it became clear that certain data are affected by the curvature of the Earth and that we needed to take this curvature into account.
„
Was there a day when everything worked?
Yes – when we were writing the final report (laughs). But seriously, there were definitely days when things just worked smoothly.
What was your biggest moment of success?
The biggest moment was when everything finally worked: we had resolved all the errors in terrain shadows and the motion vectors for cloud shadows looked good. That was the moment we knew we had successfully completed the project.
About Fabian Frauenberger

Fabian Frauenberger is a developer in the field of data science. He has implemented various machine learning solutions for LuxActive and SWISDATA, including algorithms, metrics, and data preprocessing methods, primarily used in research and development projects.
About LuxActive
LuxActive was founded in 2016 by Dr Marian Lux and consists of a team of experts specialising in cross-sector software solutions and development. Through numerous national and international research and development projects – often in a coordinating role – the company has created a wide range of platforms and API services in the field of artificial intelligence. Originally rooted in the tourism sector, LuxActive has since successfully expanded its focus to many other industries.