LLMs in a few years - Endri Deliu
"LLMs will no longer exist in a few years"
Endri Deliu worked as an AI consultant in Silicon Valley for 15 years and now helps Austrian startups in the strategic planning to develop AI applications. In the interview, he talks about current applications and risks of AI, explains why it’s not entirely straightforward to run artificial intelligence on a supercomputer, and why small, modular language models should replace large, centralised ones.
Interview by Bettina Benesch
Endri, how would you explain the concept of "artificial intelligence" to a teenager?
I would say there are different types of AI, but in general, you can define it as programs trained on data. The result is a learned program (machine learning): it possesses a certain level of intelligence and knows how to behave in environments similar to those it was trained on.
Where is AI currently being used?
Machine learning is widespread in online tools for recommendations, online searches, or in tasks like image recognition or classification. AI is also used to draft marketing emails or social media posts. This isn’t new – companies like Google have been heavily relying on machine learning for years. In the scientific field, AI is increasingly solving optimisation problems to speed up the scientific process.

(University of Vienna)
What’s new with generative AI is its ability to develop language comprehension to automate a wide range of tasks. Wherever large numbers of documents are present, it makes sense to use AI to analyse language, summarise texts, or extract key information. Lawyers, for instance, are among those who will undoubtedly benefit from these models. One of the challenges in summarising content is that documents often contain not just text but also diagrams or images in various formats. That’s the next step: AI will be able to analyse all these elements and derive an understanding from them.
As an AI Fellow at EuroCC Austria, you are working on optimising the Austrian supercomputer infrastructure for AI applications. What are the challenges of running AI on a supercomputer?
It’s primarily about the supercomputing system’s infrastructure. Historically, it has been designed for academic users. Typically, this is a PhD student or postdoc who spends a lot of time refining their topic and can afford to work on a single task for a long time.
Industrial users usually don’t have this time, and they also have different priorities, such as reproducibility and robustness – especially when it comes to bringing models to market. Of course, academic users benefit from this too, but it’s not typically at the top of their wish list. As a result, the current infrastructure isn’t yet fully optimised for running AI models on a large scale. The basics are there, and it can be used, but in the future, it will become much easier.
With ChatGPT, large language models (LLMs) became globally known. However, AI has existed long before that – just without the hype we are seeing today. What role do LLMs play in the current AI boom?
AI only gained real prominence in recent years, and the breakthrough certainly came with the understanding of language. Language is the primary means of communication in the digital age. However, LLMs have some fundamental issues: they are good at specific tasks, such as drafting emails, writing in a particular style, or mixing styles. The big question, though, is: what else are they good for? Perhaps customer support? It’s a classic example of a highly labour-intensive field and would be an excellent candidate for AI use. But it’s unclear whether LLMs are actually suitable for these requirements.
This is because LLMs work in a specific way: they predict the next word. They remember a lot and combine what they have retained, but they don’t reason or abstract well. For example, if I have an email with 500 words and one word is missing, it’s not a big problem. However, customer support is highly process-oriented; if one word is wrong, the entire process can be flawed. I’m very sceptical about whether LLMs are a good fit for customer support. Additionally, there are significant and fundamental issues regarding quality.
“
In the future, supercomputers will be better optimised to run AI models on a large scale.
„
What issues are you referring to?
I mean quality in general and the question of how to ensure and measure it on a large scale. The major problem with LLMs is that they are built in a very monolithic way: if you want to make a change for a specific domain, you cannot do so without impacting another area due to their design. LLMs are systems developed and operated as one large, interconnected unit without clear separation into independent, functioning components. So, if you modify one part, you never know whether it might break something else.
At present, large language models are being implemented on a broad scale in practice, without anyone really knowing whether they work well for the specific domain. They seem to be quite effective for summaries—if something is missing there, it’s not such a big deal. But in areas where nothing can be left out, caution is needed. In high-risk applications, humans must verify and have the final say. What LLMs already do well is supporting experts in their work: they can help accomplish tasks more quickly or inspire ideas. Nevertheless, humans must always remain in control.
It is widely known that AI hallucinates. Can you elaborate on this?
Hallucinations are a fundamental problem with LLMs. This is due to the data they are trained on: technically, they pull from the entire internet, and we know it’s not all facts – it’s also full of falsehoods. Efforts are now being made to address hallucinations after the LLM has already been built. This is where I see a fundamental issue: we need a complete rethink.
Personally, I’m not a fan of LLMs. They won’t be around in a few years. I think they represent a step that has shown us how certain things work in a particular way. It’s a research result. But we’re trying to bring this result into production too quickly. That’s the big problem. Machine learning systems are still in the developmental stage; they’re research results, not industrial products ready for deployment.
“
At present, LLMs are being implemented in practice, without anyone really knowing whether they work well for the specific domain.
„

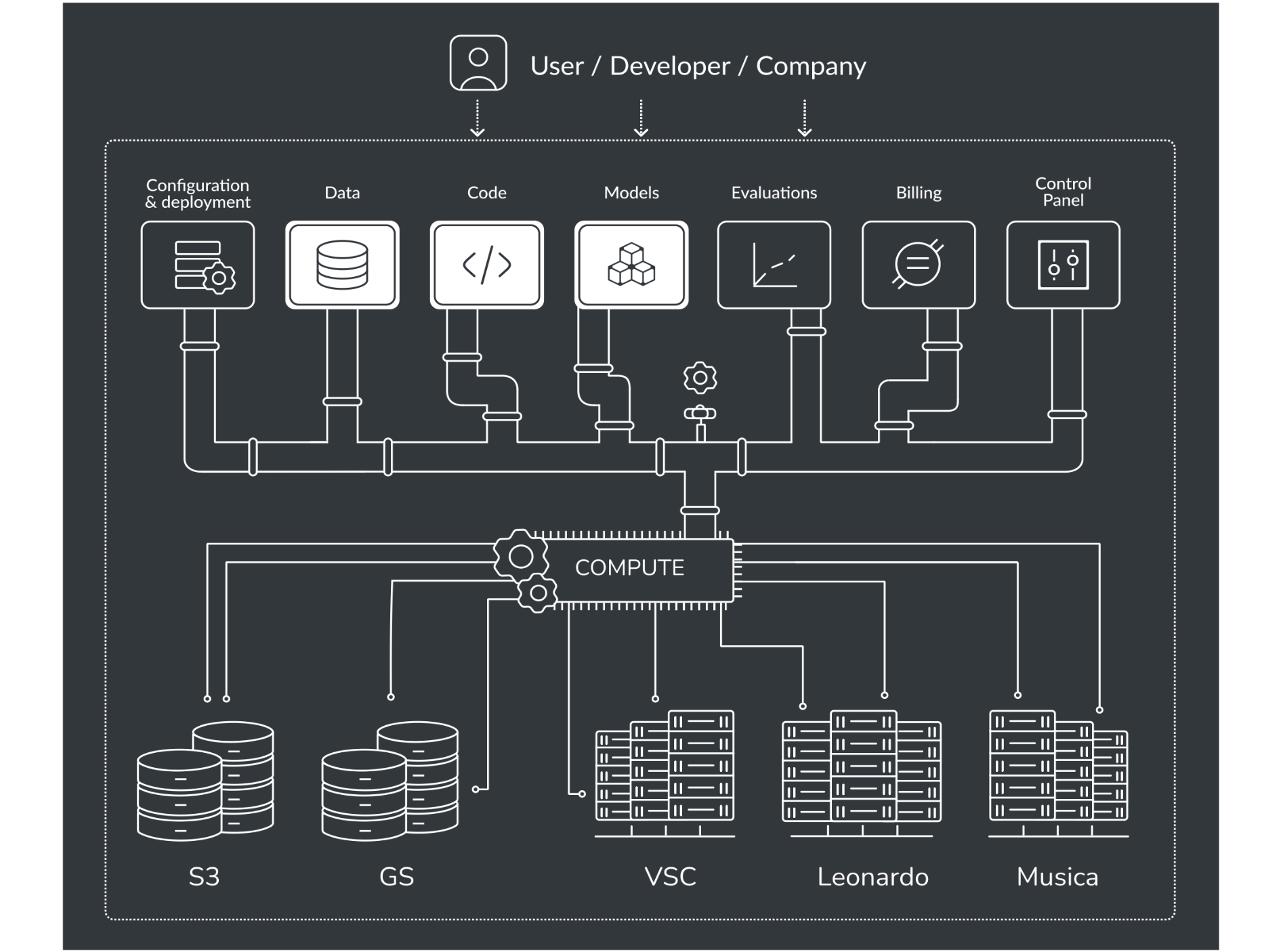
Is there an alternative to LLMs?
Yes, one is currently being developed: instead of having one massive model that does everything, the idea is to build more specialised, smaller models that are interconnected. This principle of modularity has been used in software engineering for some time and should also be applied to AI, which, at its core, is nothing more than complex software.
Is there a name for these alternatives?
There are various approaches with different names. One direction is called decentralised AI, and another involves scaling down LLMs. An alternative might be small language models (SLMs), though they’re not actually very small yet. They also need fundamental changes to make them truly applicable and controllable. When working with AI, you need control over three key aspects: data, goals, and quality. Who provides the data? Who sets the goals? Who ensures quality?
Have these questions already been answered?
No, they still need to be formulated and widely discussed. There are various schools of thought and groups working in this direction.
Can AI be controlled?
Yes, of course – through design. It needs to be designed in a way that makes it controllable. Control is everything. Who holds the power?
Who does?
“
When working with AI, you need control over three key aspects: data, goals, and quality. Who provides the data? Who sets the goals? Who ensures quality?
„
People fear that AI will dominate us. That’s not the issue – that’s science fiction. AI is too dumb, not too smart. The real issue lies in who defines what it should do and the incentives it sets.
Humans operate in hierarchical systems – our societies are somewhat hierarchical, and companies are hierarchical. When people develop AI, it’s always PhD students or postdocs who define quality standards. Then, poorly paid workers in countries like the Philippines or Kenya label the data. On one hand, you have cheap, outsourced, unskilled labour somewhere in the world. On the other, you have the PhD teams developing the AI and making all the critical decisions regarding quality. But quality means different things to different people.
Earlier, we talked about the three key elements that define functional behaviour: data, goals, and quality. Let’s focus on the goals. If a company optimises AI, it’s usually focused on two objectives: (A) engagement – getting as many users as possible to interact with their product – and (B) profit. These two things are not aligned with our personal goals as consumers. The same goes for quality: a company’s quality standards are unlikely to match mine. Right now, there’s a race to dominate this technology and define its trajectory. If we want to take an ethical path, we must address the question of control: who decides what is “good enough”?
Who do you think should decide?
The development of AI will need to involve non-technical users having a direct influence over data, goals, and quality.
How do we make that happen?
I’ve taken the time to read all 150 pages of the European Union’s AI Act. While it’s toothless and vague on many critical points, it’s a first step in the right direction because establishing regulation of any kind is necessary. One of the central requirements of the AI Act for high-risk AI is introducing a quality assurance system.
Big companies like Google and Facebook already have such systems. To meet the AI Act's requirements, they’ll just need to hire a few more engineers – problem solved. This means the AI Act ultimately fails to regulate AI in a way that benefits consumers. What truly needs to happen is the development of software and tools that empower stakeholders.
“
We – the consumers – must have a say. The same goes for institutions.
„
Who are the stakeholders of AI? On one side, the companies pursuing their own goals. On the other, us – the consumers. And we need to have a say. The same applies to institutions. They too must have a say in regulations, rules, and so on. They need access to software that enables them to directly define data, goals, and quality, thus influencing AI’s functional behaviour. The way AI models are currently built is highly centralised and monolithic. This doesn’t align with the values of a democratic, decentralised, and open system.
What role do universities play? Could they be a good place for such development?
Universities should provide a more modular alternative, enabling AI to work on behalf of a specific entity, individual, or stakeholder while aligning with their goals. We need software tools that empower users and give them control. This could potentially be an open-source solution – but it doesn’t have to be, as open-source has its own weaknesses.
What are the weaknesses of open-source?
There are many. For example, the way these systems are organised: typically, a small, simple project starts with one or two people and becomes popular. It then gets incorporated as a dependency in another, even more popular package, and eventually lands in a critical production system. When you trace the chain of open-source packages used, you often find projects that are no longer maintained or updated – yet they’re still widely used.
The risk of Trojan horses or other attacks is significant. People often claim “open-source is safer,” but that’s not true: its safety depends on whether anyone is still maintaining it. Moreover, much of the work is unpaid. You’re creating value and not getting compensated for it, and I see a problem with that.
Returning to AI in general, are there risks beyond the ones mentioned?
Other risks arise mainly when we use AI in areas where it shouldn’t be applied, or when we assign it more tasks than it can handle, which is already happening. For instance, its use in military decision-making. I don’t know exactly what’s happening there, but I suspect there’s significant interest in using AI because it can make faster decisions on the battlefield.
What can users do to use AI responsibly?
Users can loudly demand a say. By “users,” I mean scientists, domain experts, and institutions, especially universities, which are currently involved in developing these systems. They need their own AIs that represent them and can negotiate with these centralised AIs. They need tools to directly influence the three elements that define AI functionality: data, goals, and quality.
Most people don’t realise that the foundational models we have come from two or three companies. All this power is concentrated in just a few hands. There needs to be a change in the architecture of current AI systems – no more monolithic AI but decentralised systems where control is distributed among multiple partners. This won’t happen overnight; it will take years. But we need to understand the consequences of such monolithic software systems.
Considering the risks we’ve discussed, what’s the potential of AI? Where are we headed with it?
“
The foundational models come from two or three companies. All this power is concentrated in just a few hands.
„
The potential is enormous. AI is a relatively new field, but for at least 10 to 15 years, it’s been widely used in areas like classical search and recommendation systems or healthcare. Google has always used AI to reach billions of users – think about the influence of Google Search over the past two decades. Or Google Maps: I travel a lot and would be lost without it.
Now, with language essentially unleashed, we see that AI works well in document-centric areas like healthcare. AI will increasingly make inroads there, automating or simplifying many tasks through language analysis.
Where are we headed? Office work will undergo massive changes. Hopefully, we’ll be empowered by AI – using it to make tasks like email-writing easier. Less work, but more achieved. Eventually, even manual labour will be supported by AI. Robotics is the next step. Factories have used robots for decades, but these machines operate in highly controlled ways, following pre-defined movements. If a human interferes, they can’t adapt. The real breakthrough will come when robots either collaborate with humans or adapt to changing environments. AI will reach the factory floor. The next stage is the service industry: waiting tables, making coffee, helping in households.
Europe is lagging behind in both AI development and adoption. Most of the action is happening abroad, in the US and China, where the models and tools are being built. Europe has missed the boat.
Why is that?
Europe lacks venture capital. If I pitched a crazy idea to an American investor – like splitting LLMs into millions of smaller, specialised models – I’d get funding. In the US, people value bold ideas, even if they might fail. Of course, you need to be convincing – no one hands out money without reason. But the opportunity exists.
In Europe, funding tends to be public, aimed at small-scale efforts. While it supports SMEs, it’s state-driven and lacks strategic vision. If private investors fund your project, they typically support it for years, knowing these things take time to bear fruit. Public funding, however, is project-based: you apply for six months of funding, then reapply. The bureaucracy is stifling. This is not the time to be timid – it’s time to take risks. Time to invest money into people. Out of 100, maybe five or six will succeed. That’s how the US operates, and Europe would do well to follow suit.
“
Now is the time to invest money into people with ideas.
„
Do you think Europe can catch up with the US?
With a proper management and a vision: yes, it can.
What advice do you have for young AI experts pursuing a career in this field?
I’d recommend a solid education in software engineering, understanding complex distributed systems, and then getting hands-on experience with machine learning. The alternative is to follow the current university model: learn to build models first, then gradually learn software engineering. But the second path is much harder.
What originally inspired you to pursue a career in AI?
I’ve always been fascinated by natural systems and their scalability. They’re always distributed – you don’t see monolithic organisms the size of a country. This analogy, applied to how artificial systems scale, initially inspired me to build scalable software systems with a touch of intelligence. The idea of adapting to an environment drew me deeper into machine learning.