LLMs in ein paar Jahren - Endri Deliu
“LLMs werden in ein paar Jahren nicht mehr existieren”
Endri Deliu arbeitete 15 Jahre als KI-Berater im Silicon Valley und unterstützt nun österreichische Start-ups bei der strategischen Planung zur Entwicklung von KI-Applikationen. Im Interview spricht er über aktuelle Anwendungen und Risiken von KI, erklärt, warum es nicht ganz trivial ist, die künstliche Intelligenz auf einem Supercomputer laufen zu lassen, und weshalb kleine, modulare Sprachmodelle die großen, zentralistischen ablösen sollten.
Das Interview führte Bettina Benesch
Endri, wie würdest du einem Teenager den Begriff „künstliche Intelligenz“ erklären?
Ich würde sagen, es gibt verschiedene Arten von KI. Generell kann man sie aber als Programme definieren, die auf Basis von Daten trainiert werden. Das Ergebnis ist ein gelerntes Programm (Maschinelles Lernen): Es hat eine gewisse Intelligenz und weiß, wie es sich in Umgebungen verhalten soll, die jenen ähneln, auf denen es trainiert wurde.
Wo wird KI derzeit eingesetzt?
Maschinelles Lernen ist derzeit weit verbreitet in Online-Tools für Empfehlungen, Online-Suchen oder bei Dingen wie Bilderkennung oder -Klassifikation. KI wird auch verwendet, um Marketing-E-Mails oder Social-Media-Posts zu verfassen. Das ist alles nicht neu: Google und Co. setzen seit Jahren stark auf maschinelles Lernen. Im wissenschaftlichen Bereich löst die KI zunehmend Optimierungsprobleme, um den wissenschaftlichen Prozess zu beschleunigen.

(Universität Wien)
Neu hinzugekommen ist mit der generativen KI die Fähigkeit, Sprachverständnis zu entwickeln, um Aufgaben aller Art zu automatisieren: Überall dort, wo viele Dokumente vorhanden sind, lohnt sich der Einsatz von KI, die Sprache analysiert, Texte zusammenfasst oder wichtige Informationen extrahieren kann. Jurist:innen gehören sicher zu den Leuten, die vom Einsatz dieser Modelle profitieren werden.
Eine der Herausforderungen bei der Zusammenfassung von Inhalten ist, dass Dokumente nicht nur Text, sondern auch Diagramme oder Bilder in verschiedenen Formaten enthalten. Das ist der nächste Schritt: Die KI wird in der Lage zu sein, all diese Elemente zu analysieren und ein Verständnis daraus zu gewinnen.
Als AI-Fellow bei EuroCC Austria arbeitest du daran, die Infrastruktur des österreichischen Supercomputers VSC für KI-Anwendungen zu optimieren. Was ist die Herausforderung bei KI, die auf einem Supercomputer läuft?
Es geht in erster Linie um die Infrastruktur des Supercomputing-Systems: Historisch gesehen ist sie auf akademische Nutzer:innen ausgerichtet. Das ist typischerweise eine Doktorandin oder eine Postdoktorandin, die viel Zeit damit verbringt, ihr Thema zu verfeinern und die es sich leisten kann, lange Zeit an einer einzigen Sache zu arbeiten.
Industrielle Nutzer:innen haben diese Zeit meistens nicht und darüber hinaus sind für sie auch andere Dinge wichtig: Reproduzierbarkeit und Robustheit zum Beispiel – besonders wenn es darum geht, Modelle auf den Markt zu bringen. All das kommt natürlich auch den akademischen Nutzer:innen zugute, aber es steht auf ihrer Wunschliste nicht ganz oben. Daher ist die derzeitige Infrastruktur noch nicht komplett darauf ausgerichtet, KI-Modelle im großen Maßstab laufen zu lassen. Die Grundlagen existieren, man kann es nutzen, aber es wird in Zukunft viel einfacher sein.
Mit ChatGPT wurden große Sprachmodelle (Large Language Models, LLMs) weltweit bekannt. KI gab es allerdings schon lange davor – nur ohne den Hype, den wir gerade sehen. Welche Rolle spielen LLMs bei dem aktuellen Boom der KI?
KI wurde erst in den letzten Jahren richtig groß und der Durchbruch gelang sicher erst durch das Verständnis von Sprache. Sie ist das primäre Kommunikationsmittel im digitalen Zeitalter. Allerdings haben LLMs einige grundlegende Probleme: Sie machen ein paar spezifische Dinge gut, wie das Verfassen von E-Mails, das Schreiben in einem bestimmten Stil oder das Mischen von Stilen. Die große Frage aber ist: Wofür sind sie sonst noch gut? Im Kundensupport möglicherweise? Er ist das klassische Beispiel eines sehr personalintensiven Bereichs und wäre daher ein toller Kandidat für den Einsatz von KI. Es ist aber nicht klar, ob sie für diese Anforderungen tatsächlich geeignet ist.
Denn LLMs haben eine bestimmte Funktionsweise: Sie sagen das nächste Wort vorher. Sie merken sich viel und kombinieren, was sie sich gemerkt haben. Aber sie argumentieren und abstrahieren nicht gut. Angenommen, ich habe eine E-Mail mit 500 Wörtern. Fehlt in diesem Text ein Wort, ist das kein großes Problem. Aber der Kundensupport ist sehr prozessorientiert; wenn ein Wort falsch ist, ist das ganze Ding falsch. Ich bin sehr skeptisch, ob LLMs im Kundensupport gut aufgehoben sind. Noch dazu gibt es große und grundlegende Probleme in Bezug auf die Qualität.
“
In Zukunft wird es viel einfacher sein, KI-Modelle im großen Maßstab auf einem Supercomputer laufen zu lassen.
„
Welche Probleme sprichst du an?
Ich meine Qualität im Allgemeinen und die Frage, wie man sie auf breiter Ebene sicherstellen und messen kann. Das große Problem bei LLMs ist, dass sie sehr monolithisch gebaut sind: Wenn man eine Änderung für ein bestimmtes Gebiet vornehmen möchte, kann man das nicht tun, ohne einen anderen Bereich zu beeinflussen, einfach aufgrund ihrer Bauweise. LLMs sind Systeme, die als ein großes, zusammenhängendes Stück entwickelt und betrieben werden, ohne klare Trennung in einzelne und unabhängig voneinander funktionierende Komponenten. Wenn man also an einem Teil etwas ändert, weiß man nie, ob man etwas an einem anderen Teil kaputt macht.
Derzeit werden große Sprachmodelle im großen Stil in der Praxis umgesetzt, ohne dass jemand wirklich weiß, ob sie für das jeweilige Gebiet gut funktionieren oder nicht. Es scheint so zu sein, dass sie für Zusammenfassungen gut zu gebrauchen sind. Wenn da etwas fehlt, ist das nicht so schlimm. Aber in bestimmten Bereichen, in denen man nichts weglassen kann, muss man vorsichtig sein. In einem hochriskanten Anwendungsfall müssen Menschen prüfen und das letzte Wort haben. Was LLMs jetzt schon gut machen, ist, Expert:innen bei ihrer Arbeit zu unterstützen: Man kann sie nutzen, um Dinge schneller zu erledigen oder um Ideen zu bekommen. Trotzdem muss der Mensch immer die Kontrolle behalten.
Es ist allgemein bekannt, dass KI halluziniert. Kannst du dazu etwas sagen?
Halluzinationen sind ein grundlegendes Problem von LLMs. Das liegt an den Daten, mit denen sie gefüttert werden: Technisch gesehen durchsuchen sie das gesamte Internet, und wir wissen, dass dort nicht nur Fakten kursieren, sondern auch allerlei Fake. Nun wird versucht, die Sache mit den Halluzinationen zu lösen, nachdem das LLM schon gebaut wurde. Hier sehe ich das grundlegende Problem: Es braucht ein komplettes Umdenken.
Ich persönlich bin kein Fan von LLMs. Sie werden in ein paar Jahren nicht mehr da sein. Ich denke, es ist ein Schritt, der uns gezeigt hat, dass einige Dinge auf eine bestimmte Weise funktionieren. Es ist ein Forschungsergebnis. Und wir versuchen, dieses Ergebnis zu schnell in die Produktion zu bringen. Das ist das große Problem. Maschinelle Lernsysteme befinden sich im Entwicklungsstadium, es sind Forschungsergebnisse, nicht industrielle Fabriken.
“
Derzeit werden große Sprachmodelle in der Praxis umgesetzt, ohne dass jemand wirklich weiß, ob sie für das jeweilige Gebiet gut funktionieren oder nicht.
„

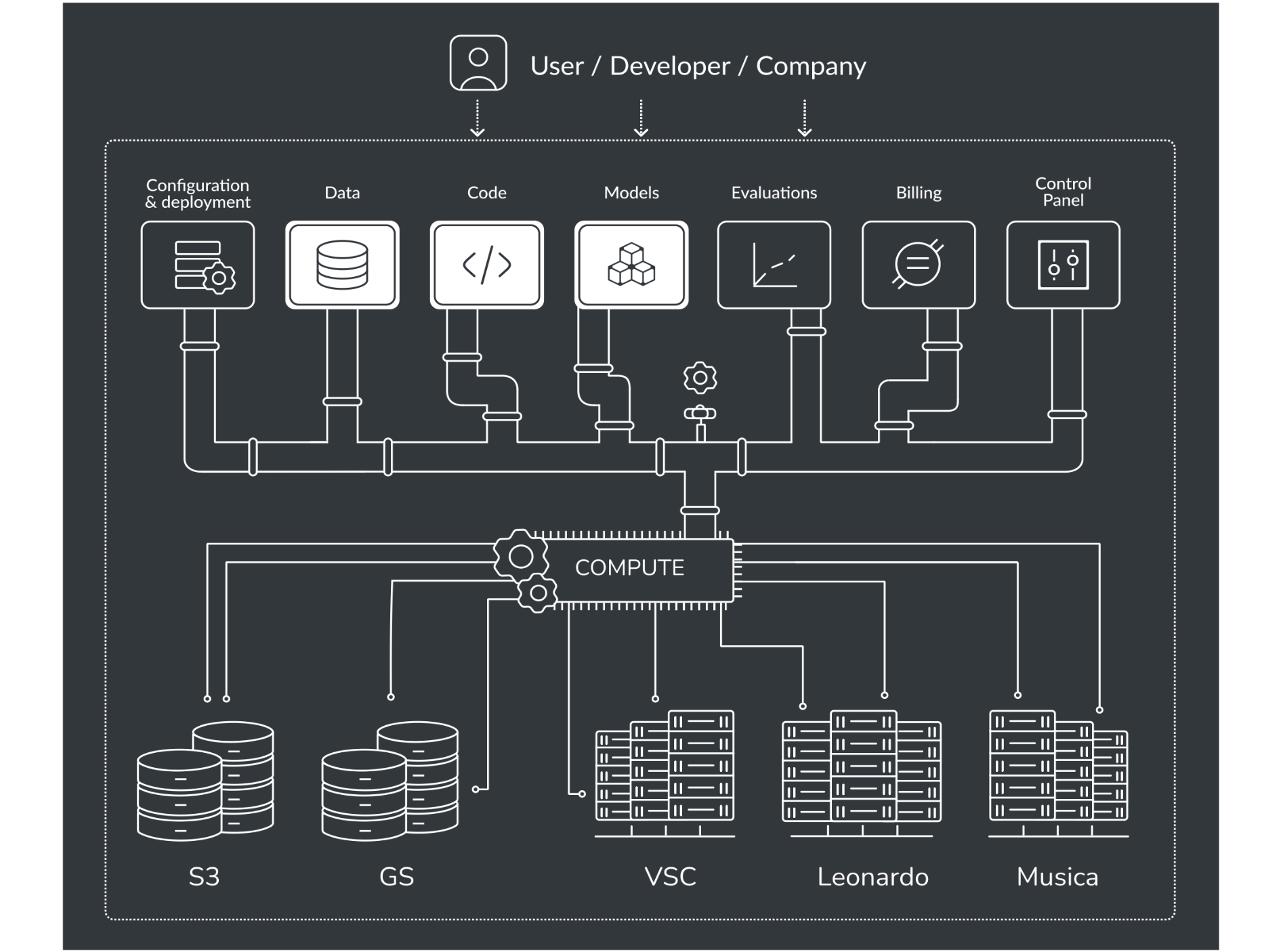
Gibt es eine Alternative zu LLMs?
Ja, sie entwickelt sich gerade: Anstatt ein riesiges Ding zu haben, das irgendwie alles macht, baut man spezialisiertere, kleinere Modelle, die miteinander verbunden sind. Dieses Prinzip der Modularität wird in der Softwaretechnik schon seit einiger Zeit verwendet. Es muss auch auf KI angewendet werden, die im Grunde genommen auch nicht mehr als komplexe Software ist.
Gibt es bereits einen Namen für diese Alternativen?
Es gibt verschiedene Richtungen, die unterschiedliche Namen haben. Ein Ding wird dezentrale KI genannt, und dann gibt es die Richtung, LLMs zu verkleinern. Eine Alternative wären kleine Sprachmodelle (SLM), aber sie sind trotzdem nicht sehr klein. Und sie müssen grundlegend verändert werden, um tatsächlich anwendbar und kontrollierbar zu sein. Wenn du mit KI arbeitest, brauchst du Kontrolle über drei wichtige Dinge: Daten, Ziele und Qualität. Wer liefert die Daten? Wer setzt die Ziele? Wer prüft die Qualität?
Sind diese Fragen bereits beantwortet?
Nein, sie müssen erst formuliert und verbreitet werden. Es gibt verschiedene Denkschulen und verschiedene Gruppen, die in diese Richtung denken.
Kann man KI kontrollieren?
Ja, natürlich. Durch das Design. Man muss sie so entwerfen, dass sie kontrollierbar ist. Kontrolle ist alles. Wer hat die Macht?
Wer hat sie?
“
Wenn du mit KI arbeitest, brauchst du Kontrolle über drei wichtige Dinge: Daten, Ziele und Qualität. Wer liefert die Daten? Wer setzt die Ziele? Wer prüft die Qualität?
„
Die Menschen haben Angst, dass uns die KI dominieren wird. Das ist nicht das Problem, das ist Science-Fiction. KI ist zu dumm, nicht zu schlau. Das wahre Problem ist, wer definiert, was sie tun soll und welche Anreize sie setzt.
Wir Menschen haben hierarchische Systeme, unsere Gesellschaften sind in gewisser Weise hierarchisch, Unternehmen sind hierarchisch. Wenn Menschen KI entwickeln, sind es immer Doktorand:innen oder Postdocs, die Qualitätskriterien definieren. Dann gibt es schlecht bezahlte Arbeitskräfte auf den Philippinen oder in Kenia, die die Daten etikettieren. Auf der einen Seite hat man also billige, ausgelagerte, ungelernte Arbeitskräfte irgendwo auf der Welt, auf der anderen Seite hat man die PhD-Teams, die diese KI entwickeln und alle wichtigen Entscheidungen in Bezug auf Qualität treffen. Aber Qualität für mich ist etwas anderes als für dich.
Wir haben vorhin über die drei großen Elemente gesprochen, die funktionales Verhalten definieren: Daten, Ziele und Qualität. Nehmen wir uns mal die Ziele heraus: Wenn eine KI von einem Unternehmen optimiert wird, passiert das mit Fokus auf zwei Dinge: A) Engagement, also „bring möglichst viele Nutzer:innen dazu, sich mit unserem Produkt zu beschäftigen“ und B) Konvergenz. Konvergenz ist Geld. Und diese beiden Dinge sind nicht unsere persönlichen Ziele als Verbraucher:innen. Das gleiche gilt für die Qualität: Die Qualitätskriterien eines Unternehmens stimmen nicht mit meinen Qualitätskriterien überein.
Aktuell findet ein Wettrennen statt, wer an der Spitze der Technologie stehen und ihren Weg bestimmen wird. Wenn man einen ethischen Weg gehen will, muss man die Frage der Kontrolle lösen: Wer entscheidet, was gut genug ist?
Wer sollte deiner Meinung nach entscheiden?
Die Entwicklung der KI wird viel damit zu tun haben, dass nicht-technische Nutzer:innen direkt Einfluss nehmen auf Daten, Ziele und Qualität.
Wie macht man das?
Ich habe mir die Mühe gemacht und alle 150 Seiten des AI-Acts der Europäischen Union gelesen. Er ist zwar zahnlos und in vielen kritischen Punkten unklar, aber er ist ein erster Schritt in die richtige Richtung, weil es erstmal notwendig ist, überhaupt eine Art von Regulierung zu schaffen. Eine der zentralen Anforderungen im AI-Act für hochriskante KI ist die Einführung eines Qualitätssicherungssystems.
Nun ist es so, dass Google, Facebook und Co. diese Systeme seit Jahren haben. Um die Anforderungen des AI-Act zu erfüllen, brauchen sie lediglich ein paar Ingenieure mehr einzusetzen und fertig. Also verfehlt der AI-Act letztendlich sein Ziel, KI im Sinne der Verbraucher:innen zu regulieren. Was wirklich vorangetrieben werden muss, ist die Entwicklung von Software und Tools, die die Stakeholder befähigen. Wer sind die Stakeholder der KI? Einerseits die Unternehmen, die ihre eigenen Ziele verfolgen, andererseits sind da wir, die Verbraucher:innen. Und wir müssen ein Mitspracherecht haben.
“
Wir - die Verbraucher:innen - müssen ein Mitspracherecht haben. Dasselbe gilt für Institutionen.
„
Dasselbe gilt für Institutionen. Auch sie müssen ein Mitspracherecht über Regulierung, Regeln usw. haben. Sie brauchen Zugang zu Software, die es ihnen ermöglicht Daten, Ziele und Qualität direkt zu definieren und damit auch das funktionale Verhalten der KI. Die Art und Weise, wie KI-Modelle derzeit gebaut sind, ist sehr zentralisiert, monolithisch. Das entspricht nicht den Werten eines demokratischen, dezentralisierten und offenen Systems.
Welche Rolle spielen Universitäten? Sie könnten ein guter Ort sein, um so etwas zu entwickeln.
Universitäten sollten eine modularere Alternative bereitstellen, die es ermöglicht, dass KI im Auftrag einer bestimmten Entität, einer Person oder eines bestimmten Stakeholders arbeitet und mit deren Zielen übereinstimmt. Wir müssen Software-Tools produzieren, die Nutzer:innen befähigen und ihnen Kontrolle geben. Möglicherweise ist das eine Open-Source-Lösung. Aber es muss nicht Open-Source sein, denn auch sie hat ihre Schwächen.
Was ist die Schwäche von Open-Source?
Es gibt viele. Eine ist zum Beispiel die Art, wie diese Systeme organisiert sind: Klassischerweise gibt es ein sehr kleines, einfaches Projekt, das von ein oder zwei Personen ausgeht und sehr populär wird. Dann wird es als Abhängigkeit in ein anderes Paket eingeführt, das noch populärer wird. Irgendwann landet es in einem kritischen Produktionssystem. Wenn man sich die Kette aller verwendeten Open-Source-Pakete ansieht, entdeckt man oft Projekte, die nicht mehr gewartet werden, geschweige denn weiterentwickelt. Trotzdem werden sie weiterhin stark genutzt.
Die Gefahr, dass sich ein Trojaner einschleicht oder das System anders angegriffen wird, ist sehr groß. Ich höre zwar die ganze Zeit „Open-Source ist sicherer“, aber das ist nicht der Fall: Es ist nicht sicher(er), es hängt davon ab, ob noch jemand dahintersteht. Dazu kommt, dass es in vielen Fällen unbezahlte Arbeit ist. Du schaffst einen Wert und wirst nicht bezahlt; damit habe ich ein Problem.
Zurück zur KI im Allgemeinen: Gibt es andere Risiken neben den erwähnten?
Die anderen Risiken entstehen hauptsächlich, wenn wir künstliche Intelligenz in Bereichen anwenden, in denen sie nicht eingesetzt werden sollte. Oder wenn wir ihr mehr Aufgaben geben, als sie bewältigen kann, was bereits geschieht. Wenn sie zum Beispiel bei Entscheidungen für das Militär eingesetzt wird. Ich weiß nicht, was dort genau passiert, aber mein Verdacht ist, dass stark darüber nachgedacht wird, KI einzusetzen, weil sie schnellere Entscheidungen auf dem Schlachtfeld treffen kann.
Gibt es etwas, das Nutzer:innen tun können, um KI verantwortungsvoll zu nutzen?
Ja, Nutzer:innen können lautstark ihr Mitspracherecht einfordern. Und mit Nutzer:innen meine ich Wissenschaftler:innen, Fachexpert:innen, auch bei den Institutionen, insbesondere den Universitäten, die derzeit an der Entwicklung dieser Systeme beteiligt sind. Sie brauchen ihre eigenen KIs, die sie repräsentieren, und ihre KIs müssen mit diesen zentralisierten KIs verhandeln. Sie brauchen Werkzeuge, die direkt die drei genannten Elemente beeinflussen, die eine KI funktional definieren (Anm.: Daten, Ziele und Qualität).
Vielen Menschen ist derzeit nicht bewusst, dass die Grundmodelle, die wir haben, von zwei oder drei Unternehmen stammen. All diese Macht ist in nur wenigen Händen konzentriert. Es muss eine Änderung in der Architektur der aktuellen KI-Systeme geben, keine monolithische KI mehr, sondern dezentralisiert. Systeme, bei denen die Kontrolle auf mehrere Partner verteilt ist. Das wird nicht über Nacht passieren, es wird Jahre dauern. Aber am Ende des Tages müssen wir realisieren, was die Auswirkungen solcher monolithischen Softwaresysteme sind.
“
Die Grundmodelle stammen von zwei oder drei Unternehmen. All diese Macht ist in nur wenigen Händen konzentriert.
„
Bei all den Risiken, die wir schon behandelt haben: Was ist das Potenzial von KI und wohin gehen wir und die KI?
Das Potenzial ist groß. KI ist als Bereich relativ neu, aber seit mindestens zehn bis 15 Jahren wird sie in Form von klassischen Such- oder Empfehlungssystemen oder im Gesundheitswesen breit eingesetzt. Google nutzt KI seit jeher und bringt sie zu Milliarden von Nutzer:innen. Denken wir nur an den Einfluss, den Google als Suchmaschine in den letzten 20 Jahren hatte. Oder Google Maps: Ich reise viel und wäre ohne Google Maps verloren. Das ist der Einfluss, den wir bisher hatten.
Und jetzt, wo die Sprache sozusagen losgelassen wurde, zeigt sich, dass KI in all jenen Bereichen gut funktionieren kann, die sehr dokumentenzentriert sind. Das Gesundheitswesen ist einer davon. KI wird dort immer mehr Fuß fassen, weil es viele Dinge gibt, die mithilfe von Sprachanalyse vereinfacht oder automatisiert werden können. Und wohin gehen wir? Büroarbeit wird sich stark verändern. Hoffentlich werden wir als Menschen ermächtigt und werden die KI nutzen, um uns zum Beispiel das Schreiben von E-Mails zu erleichtern. Weniger arbeiten, aber mehr tun.
Irgendwann wird auch manuelle Arbeit durch KI unterstützt werden. Robotik ist also der nächste Schritt. Fabriken verwenden Roboter zwar seit Jahrzehnten, aber diese Maschinen arbeiten sehr kontrolliert. Sie haben ihre Abläufe und Bewegungen, die genau festgelegt sind. Käme dem Roboter ein Mensch in die Quere, könnte sich die Maschine auf diese neue Situation nicht einstellen. Der eigentliche Durchbruch besteht darin, Roboter entweder mit Menschen zusammenarbeiten zu lassen oder sie in die Lage zu versetzen, sich an veränderliche Umgebungen anzupassen. KI erreicht also die Werkshalle. Und die nächste Stufe, würde ich sagen, ist die Dienstleistungsbranche: Tische bedienen, Kaffee machen, im Haushalt helfen.
Bei all diesen Bereichen hinkt Europa in Bezug auf die Entwicklung und den Einsatz hinterher. Im Moment passiert alles im Ausland, in den USA und China, wo die Modelle und Werkzeuge gebaut werden. Europa hat den Anschluss verpasst.
Warum ist das so?
Was Europa nicht hat, ist Risikokapital. Wenn ich jetzt rausginge zu einem amerikanischen Investor und dem erzählen würde, dass ich diese verrückte Idee habe, LLMs in Millionen kleinere spezialisierte Modelle zu splitten: Ich bekäme dafür eine Finanzierung. In den USA mag man Leute mit verrückten Ideen, die funktionieren können oder auch nicht. Natürlich musst du überzeugend sein, niemand wird dir einfach so Geld geben. Aber du kannst es bekommen.
Es hängt davon ab, in welchem Bereich Europas man sich befindet, aber im Allgemeinen bekommt man Finanzierung, wenn man sehr klein ist. Und diese Finanzierung stammt meist aus öffentlicher Hand. Es ist eine Möglichkeit, um KMU zu unterstützen, aber es ist staatlich gelenkt und hat daher einen großen Nachteil: Es ist nicht strategisch. Wenn jemand dein Projekt mit seinem eigenen privaten Geld finanziert und überzeugt ist, dass deine Idee es wert ist, finanzieren sie dich in der Regel über Jahre hinweg, denn solche Dinge brauchen Zeit, um Früchte zu tragen.
Staatliches Geld ist projektbasiert: Du bewirbst dich für ein Projekt, das vielleicht sechs Monate dauert. Danach musst du dich neu bewerben. Also gibt es diesen Aspekt der Bürokratie und insgesamt ist es nicht optimal. Jetzt ist nicht die Zeit, um schüchtern zu sein. Jetzt ist die Zeit, den Leuten das Geld nachzuwerfen. Und von hundert werden fünf oder sechs erfolgreich sein. Das ist die Art, wie man in den USA denkt und Europa täte gut daran, es ebenso zu machen.
“
Jetzt ist die Zeit, den Leuten das Geld nachzuwerfen.
„
Glaubst du, Europa kann die USA einholen?
Wenn es gut gemanagt wird und es eine Vision gibt: ja.
Kommen wir zu deinem Karriereweg und deinen Ratschlägen für junge KI-Expert:innen: Welcher Weg ist der beste, wenn man eine Karriere rund um KI anstrebt?
Ich würde sagen: Absolviere eine solide Ausbildung in Software-Engineering, lerne alles über komplexe verteilte Softwaresysteme, und mache dich dann in der Praxis mit maschinellem Lernen vertraut. Der andere Weg ist das, was Universitäten jetzt anbieten: erst zu lernen, wie man Modelle baut, um sich anschließend langsam mit Software-Engineering zu beschäftigen. Ich meine, der zweite Weg ist der viel schwierigere.
Was hat dich ursprünglich dazu bewogen, eine Karriere in der KI zu verfolgen?
Ich war schon immer von natürlichen Systemen und ihrer Skalierbarkeit inspiriert: Sie sind immer verteilt, man sieht keine monolithischen Lebewesen von der Größe eines Landes. Diese Analogie, wie künstliche Systeme skalieren, hat mein ursprüngliches Interesse geweckt, Softwaresysteme zu bauen, die ein wenig intelligent sind, aber skalierbar. Und dieser Intelligenzteil, wie man sich an die Umgebung anpasst, war das, was mich dazu gebracht hat, mich mehr mit maschinellem Lernen zu beschäftigen.