Supercomputer: Perfect home for butterflies
Supercomputer turns out to be the perfect home for butterflies
At first glance, butterflies and supercomputers have nothing in common. However, upon closer inspection, they are more deeply connected than one might think—at least in the world of Friederike Barkmann, an ecologist at the University of Innsbruck. Using artificial intelligence (AI) and a supercomputer, she has significantly simplified the identification of butterflies based on photos. EuroCC Austria supported her in training the model on one of Austria’s high-performance computers. Now, the first interim results are in: the model achieves an accuracy rate of 97%, and the computation time has been reduced by 90%.
Butterflies are not only popular photography subjects but also crucial indicators of biodiversity. Therefore, monitoring these insects is of great importance for environmental protection. In Austria, the monitoring is carried out as part of the initiative "Viel-Falter Monitoring" (viel-falter.at), in which scientists from the University of Innsbruck work together with volunteers. In addition to the systematic observations, many volunteers also collect incidental sightings of butterflies.
Over the past few years, volunteers have uploaded several hundred thousand images of native butterflies via the free Butterfly App (schmetterlingsapp.at) from Blühendes Österreich, a non-profit initiative of the BILLA Private Foundation. These images serve as valuable data sources for purposes such as Red List assessments or species distribution maps—and as the foundation for Friederike Barkmann’s research on new machine learning models.

The identification of butterflies has traditionally been carried out by experts, which is a very time-consuming and costly process. To simplify this process, the idea arose to train a machine learning model—letting artificial intelligence take flight alongside the butterflies.
Testing various models to find the one
Traditionally, identifying butterflies and verifying uploaded photos has been a manual task for experts. It’s not only a time-consuming and costly process, but also an unreliable one - after all, no expert can classify all the specimens. This issue led to the idea of letting artificial intelligence (AI) do the job and to train a machine learning model. The goal is to test various models to determine which one best identifies butterflies and other animals. This would not only give wings to the project of butterfly identification but also benefit other biodiversity initiatives. However, achieving this requires enormous amounts of data, which, in turn, demands significant computing power.
Accelerated data processing with machine learning
Ecologist Friederike Barkmann worked with 529,835 images of 162 butterfly species to train different machine learning models. In projects like this, the more images available for a given species, the easier it is for the model to correctly classify them. But biodiversity data typically exhibit a phenomenon known as "class imbalance," where some species have over 10,000 photos, while others have as few as ten. The challenge is to ensure that "smaller" species are weighted appropriately in the machine learning model.



Parallel processing improves performance
Barkmann began her work on the University of Innsbruck’s supercomputer, LEO5. Modern high-performance computers like LEO5 are equipped with efficient Graphics Processing Units (GPUs), which are particularly well-suited for training AI models. However, a single GPU is not as powerful as multiple GPUs working together. That’s why supercomputing experts connect multiple processors using a method known as "parallelisation".
Initially, Barkmann trained the model using a massive dataset on a single GPU. During the lengthy computation time, she could have leisurely gone for a walk and butterfly-watching on the city outskirts. However, supercomputing expert Andreas Lindner from EuroCC Austria saw a way to optimise the process and implemented parallelisation on four GPUs on the Innsbruck supercomputer. This reduced the training time for a single epoch (out of 50 total) from two hours to just twelve minutes—a 90 % time savings. Furthermore, the accuracy of the model was exceptionally high: as of early December 2024, the test dataset achieved a 97 % identification accuracy, meaning 97 % of butterflies were correctly classified.
On multiple GPUs, the training time for one epoch was reduced from two hours to twelve minutes, representing a 90 percent time savings. The accuracy was also very high: In the test dataset, it reached 97 percent in early December 2024. This means that 97 percent of the butterflies were correctly identified.
High-quality data leads to accurate models
For every AI image recognition tool, the rule is simple: the more training images available, the more accurate the model can become. However, Barkmann’s project also included butterfly species with relatively few images. Here, the class imbalance issue arose again: while some species had 5,000 images, others had only 70. To address this, Barkmann augmented the dataset by editing images—rotating them or cropping smaller sections—so that the model had more data to learn from. Despite these efforts, species with fewer images remained more difficult to classify accurately. The study found that when a species had at least 1,662 images, the model could predict it with at least 90 % accuracy.
The model works—now it’s being optimised
Barkmann isn’t stopping there. "Even though 97 or 90 % accuracy is impressive, it still means that many species are misclassified," she explains, particularly those with limited image data. After the successful training on LEO5, EuroCC Austria facilitated access to the Italian supercomputer LEONARDO, which is approximately 400 times more powerful than Innsbruck’s system. Given the enormous dataset and complex models, even greater computational power is now required. The current plan is to test and optimise various models on LEONARDO to improve recognition of rare butterfly species.
In early 2025, Barkmann plans to publish the first part of her research in her master’s thesis for the University’s Data Science programme. The second part is expected to be published as part of her PhD thesis by the end of 2025.
About EuroCC Austria
EuroCC Austria is the national competence center for High-Performance Computing (HPC), High-Performance Data Analytics (HPDA), and Artificial Intelligence (AI). It supports startups, universities, and public institutions in accelerating and optimising projects using supercomputing and AI.
Do you need supercomputing power? Contact us at info@eurocc-austria.at
Links
Out of her work with more than 500,000 images of butterfly and moth species, Friederike Barkmann developed the largest dataset of Austrian butterflies and moths worldwide, published in August 2025 in Scientific Data (Nature). The dataset is publicly available to scientists across the globe: Machine learning training data: over 500,000 images of butterflies and moths (Lepidoptera) with species labels.
Department of Ecology, University of Innsbruck: https://www.uibk.ac.at/de/ecology/
Butterfly app: https://www.schmetterlingsapp.at
Viel-Falter Monitoring: www.viel-falter.at
Code for LEONARDO on Github: https://github.com/FriederikeBarkmann/CNN_butterfly_identification
First trained model: https://huggingface.co/RikeB/CNN_butterfly_identification
What are Machine Learning, Deep Learning and Artificial Intelligence?
Machine learning means that a system independently recognizes patterns and relationships. The algorithm learns from billions of provided data points, enabling it to make predictions, calculate probabilities, or identify connections. A commonly used approach in machine learning is to build an artificial neural network with multiple layers. Each layer is derived from the previous one.
For the system to function, it must be trained. The artificial neural network receives both input data and the desired output data. Applied to image recognition, as in the case of butterflies, it works as follows: There is an input layer (e.g., a photo) and an output layer (the butterfly species). In between are hidden layers, which help the model compute the correct answer. (See image on the right.)
In the past, it was not possible to build networks with a large number of layers. However, advanced algorithms now allow for training networks with many layers. This led to the term "Deep Learning", referring to deep neural networks. Deep Learning is therefore a subfield of Machine Learning.
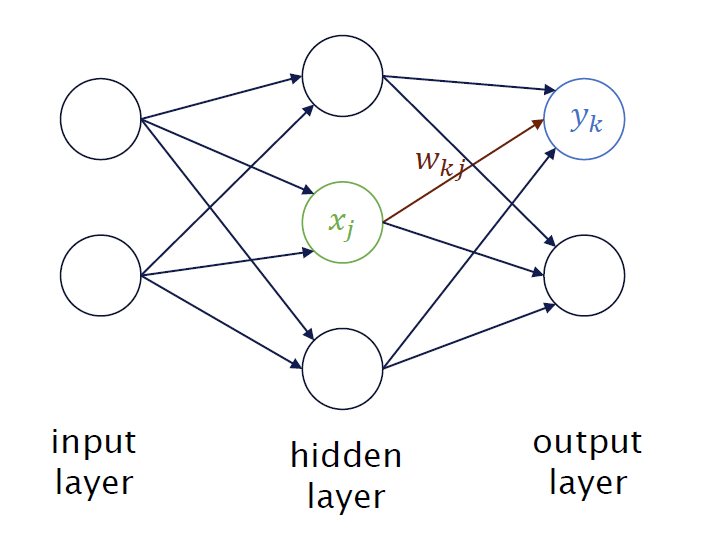
At the end of training, the computer attempts to recognize certain features on its own—features so complex that they are often difficult for humans to grasp. The results are often correct, but not always, as AI also makes mistakes. However, it can detect patterns that humans might not always understand. This is where the term “Artificial Intelligence” comes from, as the system’s performance appears intelligent.
Another interesting fact: Neural networks are not a recent discovery. The foundation was already laid in the mid-20th century. What we have today, however, is significantly more computing power thanks to powerful supercomputers. Some things that are now possible would have been technically unfeasible just a few years ago. Only with modern high-performance computers have Machine Learning, Deep Learning, and Artificial Intelligence truly become feasible.