Supercomputer: Domizil für Schmetterlinge
Supercomputer entpuppt sich als perfektes Domizil für Schmetterlinge
Auf den ersten Blick haben Schmetterlinge und Supercomputer nur denselben Anfangsbuchstaben gemeinsam. Wer allerdings genau hinsieht, erkennt, dass beide enger verbunden sind als gedacht – jedenfalls in der Welt von Friederike Barkmann, Ökologin an der Universität Innsbruck: Sie hat es mit Künstlicher Intelligenz (KI) und einem Supercomputer geschafft, das Bestimmen von Schmetterlingen anhand von Fotos deutlich zu erleichtern. EuroCC Austria hat sie dabei unterstützt, das Modell auf einem der österreichischen Hochleistungsrechner zu trainieren. Nun liegen die ersten Zwischenergebnisse vor: Die Treffergenauigkeit liegt bei 97 Prozent und die Rechenzeit wurde um 90 Prozent reduziert.
Schmetterlinge sind nicht nur beliebte Fotomotive, sondern auch bedeutende Indikatoren für biologische Vielfalt. Daher ist das Monitoring dieser Insekten für den Umweltschutz enorm wichtig und wird in Österreich im Rahmen des Viel-Falter Monitorings (viel-falter.at) von Wissenschaftler:innen der Universität Innsbruck gemeinsam mit Freiwilligen durchgeführt. Neben diesen systematischen Beobachtungen sammeln viele Freiwillige auch Zufallsbeobachtungen von Schmetterlingen.
Über die kostenlose Schmetterlings-App (schmetterlingsapp.at) von Blühendes Österreich, der gemeinnützigen BILLA-Privatstiftung, haben Freiwillige in den letzten Jahren mehrere hunderttausend Bilder heimischer Falter gesammelt. Sie dienen als wertvolle Informationsquelle, etwa für Rote-Liste-Bewertungen oder Verbreitungskarten von Arten – und als Basis für Friederike Barkmanns Forschungen an neuen Machine-Learning-Modellen.

Die Bestimmung von Schmetterlingen erfolgt traditionellerweise durch Expert:innen, was sehr zeit- und kostenintensiv ist. Um diesen Prozess zu erleichtern, entstand die Idee, ein Machine-Learning-Modell zu trainieren und so Künstliche Intelligenz mitflattern zu lassen.
Das Ziel: Machine-Learning-Modelle auf Herz und Nieren testen
Die Bestimmung von Schmetterlingen und die Kontrolle der hochgeladenen Fotos erfolgt traditionellerweise durch Expert:innen, was sehr zeit- und kostenintensiv ist. Und nicht immer ist ein Profi zur Hand, um einen Falter zuzuordnen. So entstand die Idee, ein Machine-Learning-Modell zu trainieren, also Künstliche Intelligenz (KI) mitflattern zu lassen. Ziel ist es, verschiedene Modelle zu testen, um herauszufinden, welches davon Schmetterlinge und andere Tiere am besten erkennt. Somit würde nicht nur die Schmetterlingsbestimmung stärkere Flügel und mehr Auftrieb erhalten, sondern auch verschiedene andere Biodiversitäts-Projekte. Was es dazu allerdings braucht? Riesige Datenmengen. Und die wiederum brauchen geballte Computerpower.
Mit Machine Learning enorme Datenmengen rasch verarbeiten
Die Ökologin Friederike Barkmann trat mit 529.835 Bildern von 162 Schmetterlingsarten an, um verschiedene Machine-Learning-Modelle zu trainieren. Bei einem solchen Projekt gilt: Je mehr Fotos es von einer Art gibt, umso einfacher ist es für das jeweilige Modell, die Arten richtig zu bestimmen. Für Biodiversitätsdaten ist es typisch, dass es von einer Art 10.000 oder mehr Fotos gibt und von einer anderen nur zehn. Fachleute sprechen in so einem Fall von Class Imbalance (Klassenungleichgewicht). Es geht also darum, die “kleinen” Arten im Machine-Learning-Modell stärker zu gewichten.



Parallel läuft’s besser
Die Forscherin startete auf dem Supercomputer der Universität Innsbruck, LEO5. Moderne Hochleistungsrechner wie LEO5 sind mit effizienten Grafikkartenprozessoren ausgestattet (Graphics Processing Units, GPUs), die sich hervorragend für das Training von KI-Modellen eignen.
Eine GPU allein ist allerdings nicht so leistungsfähig, wie mehrere zusammen. Darum verbinden Supercomputing-Expert:innen mehrere Prozessoren miteinander. In der Fachsprache wird das als Parallelisierung bezeichnet. Erst arbeitete Barkmann mit einer riesigen Datenmenge auf einer einzigen GPU und hätte während LEOs Rechenzeit gemütlich ein paar Schmetterlinge am Stadtrand fotografieren können. Supercomputing-Experte Andreas Lindner von EuroCC Austria erfuhr von dem relativ langwierigen Prozess und setzte die Parallelisierung auf dem Innsbrucker Supercomputer auf vier GPUs um. So reduzierte sich die Rechenzeit für eine Trainingsepoche (von insgesamt 50) von zwei Stunden auf zwölf Minuten. Das entspricht einer Zeitersparnis von 90 Prozent. Und auch die Treffergenauigkeit war sehr hoch: Im Testdatensatz lag sie Anfang Dezember 2024 bei 97 Prozent. Das bedeutet, 97 Prozent der Schmetterlinge wurden korrekt erkannt.
Durch das Arbeiten auf mehreren GPUs gleichzeitig reduzierte sich die Rechenzeit für eine Trainingsepoche von zwei Stunden auf zwölf Minuten. Das entspricht einer Zeitersparnis von 90 Prozent. Und auch die Treffergenauigkeit war sehr hoch: Im Testdatensatz lag sie bei 97 Prozent. Das bedeutet, 97 Prozent der Schmetterlinge wurden korrekt erkannt.
Viele gute Daten ergeben ein genaues Modell
Beim Training jedes KI-Bilderkennungstools gilt: Je mehr Fotos als Ausgangsmaterial vorliegen, umso genauer kann das Modell trainiert werden. Es gab in Barkmanns Projekt allerdings auch Schmetterlingsarten, von denen vergleichsweise wenige Fotos vorhanden waren. Hier haben wir sie wieder, die Class Imbalance: Neben 5.000 Bildern der einen Art fanden sich in Barkmanns Datensatz mitunter auch mal nur 70 von einer anderen. Hier behalf sich die Forscherin, indem sie die vorhandenen Fotos bearbeitete; sie zum Beispiel drehte, oder kleinere Ausschnitte verwendete. So hatte das Modell mehr Futter für das Training. Dennoch war die Basis hier dünner als bei den häufiger vorkommenden Arten und die Treffsicherheit entsprechend gering. Ab einer Anzahl von mindestens 1.662 Bildern pro Art konnten alle Schmetterlinge mit mindestens 90-prozentiger Genauigkeit vorhergesagt werden.
Das Modell funktioniert und wird nun optimiert
Doch Barkmann hat mehr vor: „Auch wenn 97 oder 90 Prozent schon hohe Werte sind, heißt es auch, dass viele Arten falsch bestimmt werden", sagt die Wissenschaftlerin. Das gilt vor allem für jene Arten, für die wenig Bilder zur Verfügung stehen. Nach dem erfolgreichen Training auf LEO5 ermöglichte EuroCC Austria den Zugang zum italienischen Supercomputer LEONARDO, der etwa 400-mal leistungsstärker ist als der Innsbrucker Hochleistungsrechner. Denn die riesigen Datenmengen und aufwändigen Modelle brauchen jetzt nochmal höhere Rechenleistung. Der aktuelle Plan ist, verschiedene Modelle auf LEONARDO zu testen und zu optimieren, damit auch die kleinen Schmetterlingsklassen gut erkannt werden.
Anfang 2025 möchte die Ökologin den ersten Teil ihrer Studien in ihrer Masterarbeit für den Universitätslehrgang Data Science veröffentlichen. Der zweite Teil soll bis Ende 2025 im Rahmen ihrer Doktorarbeit wissenschaftlich publiziert werden.
Über EuroCC Austria
EuroCC Austria ist das nationale Kompetenzzentrum für High Performance Computing, HPDA und Künstliche Intelligenz, und unterstützt Start-ups, Universitäten und die öffentliche Verwaltung dabei, Projekte mit Hilfe von Supercomputing und KI schneller und effizienter abzuwickeln.
Haben Sie Bedarf an Supercomputing-Power? Kontaktieren Sie uns! office@eurocc-austria.at.
Weiterführende Links
Aus ihrer Arbeit mit mehr als 500.000 Bildern von Schmetterlings- und Falterarten entwickelte Friederike Barkmann den weltweit größten Datensatz österreichischer Schmetterlinge und Falter, der im August 2025 in Scientific Data (Nature) veröffentlicht wurde. Der Datensatz ist weltweit für Wissenschaftler:innen frei zugänglich: Machine learning training data: over 500,000 images of butterflies and moths (Lepidoptera) with species labels
Institut für Ökologie, Universität Innsbruck: https://www.uibk.ac.at/de/ecology/
Schmetterlings-App: https://www.schmetterlingsapp.at
Viel-Falter Monitoring: www.viel-falter.at
Code für LEONARDO auf Github: https://github.com/FriederikeBarkmann/CNN_butterfly_identification
Das erste trainierte Modell: https://huggingface.co/RikeB/CNN_butterfly_identification
Was sind Machine Learning, Deep Learning und Künstliche Intelligenz?
Machine Learning bedeutet, dass ein System selbstständig Muster und Zusammenhänge erkennt. Der Algorithmus lernt aus Milliarden zur Verfügung gestellter Daten und kann so Vorhersagen treffen, Wahrscheinlichkeiten berechnen oder Zusammenhänge erkennen. Ein häufig verwendeter Ansatz für maschinelles Lernen ist es, ein künstliches neuronales Netzwerk mit unterschiedlichen Layern (Schichten) aufzubauen. Jeder Layer wird aus dem davor errechnet.
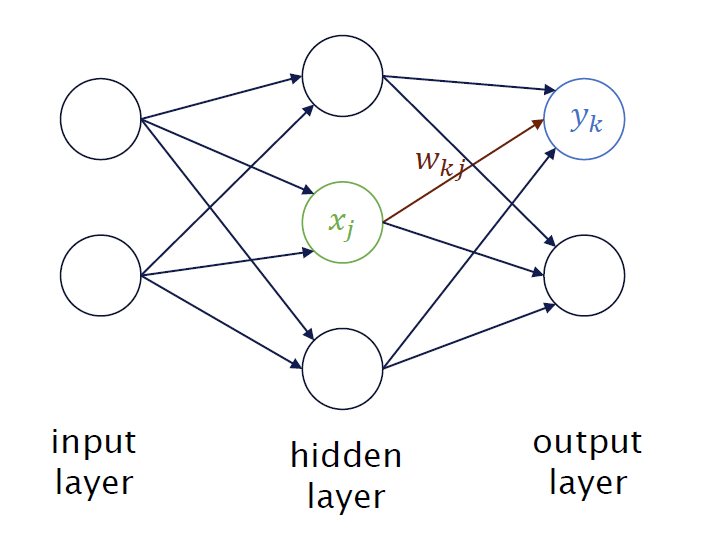
Damit das System funktioniert, muss es trainiert werden. Das künstliche neuronale Netzwerk erhält sowohl Eingangsdaten als auch die gewünschten Ausgangsdaten. Umgelegt auf Bilderkennung wie bei den Schmetterlingen sieht das folgendermaßen aus: Es gibt den sogenannten Input Layer (zum Beispiel ein Foto) und den Output Layer (die Art des Schmetterlings). Dazwischen liegen Hidden Layer, mit denen das Modell die Antwort berechnet. (s. Bild rechts)
Früher war es nicht möglich, Netzwerke mit einer großen Anzahl an Layern zu bauen, mittlerweile gibt es jedoch ausgeklügelte Algorithmen, um auch Netzwerke mit einer größeren Anzahl an Layern zu trainieren. Daraus ist der Begriff „Deep Learning“ im Sinne von Deep Neural Networks entstanden. Deep Learning ist also ein Unterbereich von Machine Learning.
Am Ende des Trainings versucht der Computer, selbst gewisse Merkmale zu erkennen, die so kompliziert sind, dass sie von Menschen oft schwer zu erfassen sind. Aber die Ergebnisse sind oft richtig – allerdings nicht immer, denn auch die KI macht Fehler. Sie kann allerdings Dinge erkennen, die der Mensch nicht immer durchschaut. Daher stammt der Begriff „Künstliche Intelligenz“, weil es so intelligent erscheint, was das System macht.
Auch interessant zu wissen: Neuronale Netzwerke sind keine Entdeckung unserer Zeit. Der Grundstein wurde schon Mitte des 20. Jahrhunderts gelegt. Was wir heute allerdings haben, ist viel mehr Rechenleistung durch leistungsstarke Supercomputer. Manche Dinge, die jetzt möglich sind, wären vor einigen Jahren technisch nicht machbar gewesen. Erst die heutigen Hochleistungsrechner haben Machine Learning, Deep Learning und Künstlicher Intelligenz die Türe geöffnet.